
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
Team Gardn999
The Differential Privacy Synthetic Data Challenge
4th Place - $5,000 Prize
*An additional $4,000 was awarded for posting their full code solution in an open source repository.
About the Team
John Gardner received a Bachelor of Science in computer science, mathematics, and physics from the University of Washburn in 1998 and a Ph.D. degree in physics from the University of Kansas in 2006. He is a long time member of TopCoder and has participated in a large variety of algorithm development competitions.
Team Gardn999 used the NIST Collaboration Space as their open source repository and can be accessed here. *Note that other contestant source code may also be found on this site.
The Solution
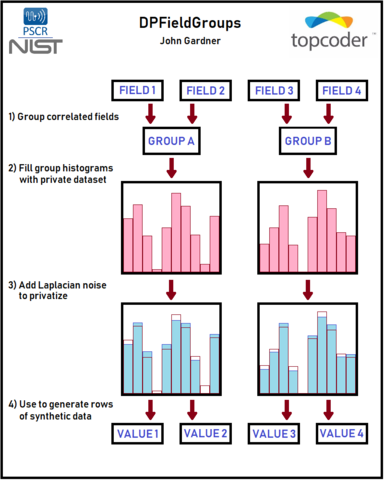
The goal of DPFieldGroups is to create differentially private synthetic data while retaining as much useful information as possible about the original dataset. It is able to be effectively used on datasets with a large number of fields with a large range of possible values. The epsilon parameter can be adjusted to manage the trade-off between level of privacy and information preservation. Team Gardn999 took the following steps to create their solution:
- Group Correlated Fields: Public data similar to that being privatized is studied to identify highly correlated fields and to understand the field value distributions. These are then identified in the data to be privatized and highly correlated fields are grouped together.
- Fill Group Histograms with Private Dataset: For each of these groups, a histogram is created for the purpose of counting the number of occurrences of every possible combination of values of all fields in the group. These bins are then filled with the data to be privatized.
- Add Laplacian noise to privatize: For privatization, Laplacian noise is added to every bin with scale proportional to the number of groups. With highly correlated fields, it is expected that most of the bins will be empty before noise is added. To prevent a massive increase in the percentage of non-zero bins after noise is added, a threshold cut is made. The bin count after adding noise must be at least as large as the threshold or be set to zero. Although it adds a risk of removing some rare true occurrences, it greatly reduces the negative effect of the added noise.
- Use to Generate Rows of Synthetic Data: Synthetic data is generated by selecting a random bin for each group with probability weighted by the noisy bin counts. The field values corresponding to each group's selected bin are written out as a single row of synthetic data.