
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
NIST Speech Signal to Noise Ratio Measurements
How much do algorithms help?
A Signal to Noise Ratio (SNR) Metric for speech in noise.
The NIST Speech SNR Measurement
In the service of the NIST mission to facilitate industrial advanced technology development, we focus on measurement science and standards development. Since the Smart Spaces of the future will require sensor based interfaces, particularly audio based for speech and speaker recognition, we have developed a signal-to-noise measurement method that will allow more precise measurement of speech signal strength in relatively high background levels. This is designed to facilitate the development of noise reduction algorithms as applied to speech acquired from a variety of sources including microphone arrays.
Broadly, speech is composed of voiced and unvoiced parts, for example the word six being spoken as a phonetically as the four phonenems /s/ /ih/ /k/ /s/, with the two /s/ phones being unvoiced, and having a much lower volume than the /ih/ phone.
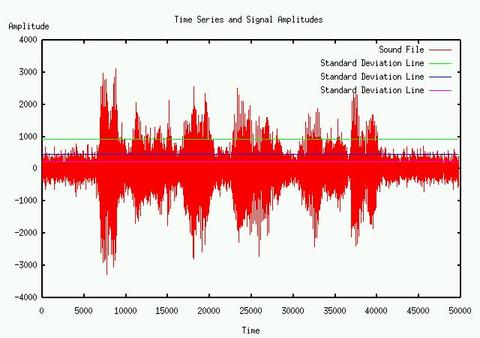
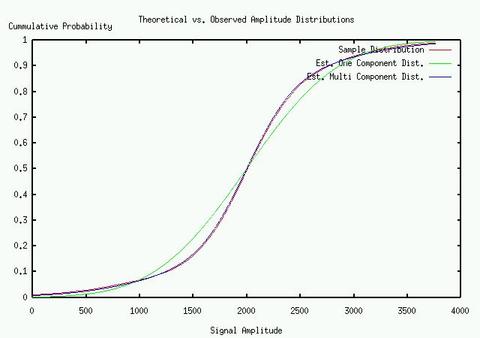
Since we are never allowed to observe speech without some degree of background noise, we have developed a method based on sequential Gaussian mixture estimation. Experimental measurements of background noise amplitudes received at our microphone array are well represented by a single Gaussian component, and tested with a Kolmogrov-Smirnov statistic for goodness of fit. A good degree of fit to a single component indicates that no speech is present in a given sample. If a single component hypothesis can be rejected, then we proceed to fit a two component model to the sample time series. A good fit to a two component model might indicate a non-speech speech signal, or speech in a very high level of background noise which masks the unvoiced portion of the speech. If a two component model does not provide a reasonably good fit, we proceed to a three component model, which indicates that there is a fairly good signal-to-noise ratio.
These mixtures are estimated using the classic Expectation Maximization technique, but modified to reflect a constraint that all of the means are equal and zero. We provide a highly optimized C-language implementation of this estimation algorithm as part of our open source toolkit. We take as the SNR estimate as the ratio of the smallest standard deviation to the largest on the decibel scale of 20*log10(s/n).
The pictures show the SNR algorithm estimates of the component standard deviations, from a single microphone and our microphone array. We can see that we go from nine to twenty-one db in the same setting using a delay and sum beam former, and a codec filter that limits the frequency from about 100Hz. to 8,000Hz.
The SNR tool is provided in the CVS release.
|
|
|
|