
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
NIST Data Flow System II - User's Guide - Draft Version - Chapter 2
RETURN TO DOCUMENT TABLE OF CONTENTS
Chapter 2: Table of Contents
NIST Data Flow System II Introduction
Example of a multimodal application
Main components of the framework
Advantages of using a data flow
Optimized data transport
Language binding
-- Java
-- Octave
Limitations
Complex System simulations
In this section, we introduce the main concepts and key points of the data flow system. We also highlight the advantages of using a data flow system.
NIST Data Flow System II Introduction
The NIST Data Flow System II is a middleware whom purpose is to move data between client nodes in a publishing-subscribing manner. Clients can produce and/or consume streams of data (also called flows). An application is thus represented as an application graph, where logical blocks (or client nodes) perform successive operations on data pipelines.
Example of a multimodal application
In this example, we describe an application, which recognizes words after a proper identification of the speaker. This application has real-time constraints. Due to the processing requirements, it is not feasible to have it running on a single computer. So we implement it using several logical blocks (or client nodes), which communicate by exchanging data, and we allocate these client nodes on two computers. The NDFS-II is used to transport the buffers of data encapsulated in flows between client nodes.
Figure 2.1.
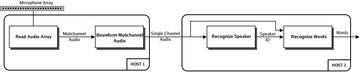
A simple multimodal application composed of four client nodes exchanging data allocated on two hosts.
Since all the computation and data acquisition in this application may be beyond the ability of a single PC, we used the NDFS-II to transport data between client nodes. In this example client nodes are spread on two hosts. As shown on Figure 1, the entire application is pipelined into four steps.
- First data from the Microphone array are captured by the client Read Audio Array and made available on the NDFS-II network as a Multichannel Audio flow.
- The client Beamform Multichannel Audio subscribes to the Multichannel Audio Flow, and applies a beamforming algorithm on them to bear on the speaker. As a result, a Single Audio Channel flow is produced and made available for subscription.
- The client Recognize Speaker subscribes to the Single Audio Channel flow and performs speaker identification on these data. If a match is found, the client node puts the ID of the speaker in a Speaker ID flow.
- Finally the client Recognize Words recognizes words as its name suggests. In order to operate properly, it subscribes to both the Speaker ID flow and the Single Audio Channel flow. With these data the client node is able to load and use the trained profile of the speaker to recognize words, which are encapsulated inside the Words flow.
In this application, we use the middleware to transport data between client nodes either within a machine or between machines via the network.
Main components of the framework
In this section we introduce the main components of the NDFS-II.
- Client node: An executable program that uses the NDFS-II library to consume and/or produce flows. There are also client nodes that do not use flows, but provide control over the NDFS-II network such as the Control Center.
- Flow: A buffered data stream connecting a producer node to an arbitrary number of consumer nodes and providing distributed data transport. These flows have a type (e.g.: Flow_Multichannel_Audio), a name (e.g.: arrayOut), and a connection ID. It is possible to add more properties to flow (ex: bits=24 rate=22050 channels=64). You also have the possibility to create your own type of flows depending on your needs.
- Duplicator: An executable program that handles the distribution of the flow between the clients, either on a single host or to network connected hosts on a network. As a user, you will never have to directly handle duplicators.
- Buffers: The basic unit of data exchanged among client nodes via flows when they emit data to, or consume data from a flow. Each flow has its own buffer characteristics, in particular the maximum size that a buffer can be, and the data type being transmitted. Buffers are also called data blocks.
- Application: An application is a flow domain in which the clients run. An application is thus represented as an arbitrary number of client nodes exchanging data. The NDFS-II library provides a default flow domain. Users can define their own domains, making it possible to have several domains, i.e., several NDFS-II application running on the same physical subnet. A physical machine can only be part of one domain. The domain is set up when starting the data flow server.
- Data flow server: The server that centralizes all the information for a given application. The information is in particular what and where are the client nodes on the network and which flows they provide or consume. A Data flow server can only belong to one domain.
- SHM, Shared Memory: This facility is used by a given host to exchange data between duplicators and clients, since it is much faster than any other inter-process communication mechanisms.
- Host, System or Machine: A computer participating in an application graph by running a data flow server, and any number of client nodes.
Advantages of using a data flow
Using a data flow system has a lot of advantages, especially for data driven applications where processing requirements are beyond the computational power provided by a single host. The most obvious advantage is that you don't have to handle the transport of your data between client nodes. This task is delegated to the NDFS-II. To connect client nodes together through flows, you don't have to deal with the locations of your client nodes in the network but instead you specify which flows you want to connect. It allows you to focus on specific problems rather than spending time on how to transport your data.
In order to achieve the data transport and address the needs of as many people as possible, the data flow has to have some key capabilities. NDFS II is
- Dynamic: A host can join or leave an application at any time. Client nodes can also join or leave an application at any time and in the same manner they can create or destroy flows whenever they need. The system has been designed to support this kind of behavior.
- Decentralized: There is no central server in the NDFS network. If a server or a client node crashes, it won't make the system unstable and unusable. Of course client nodes consuming data from a producer client node, which crashes, will be affected. But they will only be affected by not receiving data.
- Extensible: You can define your own kind of flows. These flows can transport any kind of data or metadata. Flows work as "plug-ins" meaning that you don't have to recompile the whole system to use them.
- Cross platform: Because people have different needs where some programs are tied to a specific architecture (e.g.: a camera only supported under Windows), the NDFS-II runs on Unix/Linux, Mac OS X and Windows XP. The middleware will transport the data independently of the operating system.
- Multi-language: The system has been developed in C++, and it provides an object oriented API to use. However, users can develop client nodes using Java thanks to our wrapper. So an application can be composed of a Java client node capturing video and feeding a face tracker client node written in C++.
- Optimized: The transport is optimized to increase the performance. Data are transported within a host using shared memory and via the network using TCP/IP between hosts. If a producer client node sends a flow to two consumer client nodes located on the same machine, the data will only be transported once over the network.
- Modular: It promotes the development of reusable client nodes with well-defined interfaces. Several applications may use a Word Recognizer, for example.
Optimized data transport
The NDFS-II has been designed to support applications requiring high data transfer rates. It takes advantage of gigabyte networks and avoids redundant copying of data to minimize the bandwidth and thus speed up the communication between client nodes. A goal at the beginning of the project was to transport the data as efficiently as possible. In order to optimize the transport, we introduce the concept of duplicators. Duplicators are stand-alone programs handling flow within hosts. There is one duplicator per instance of flow per host.
Figure 2.2.
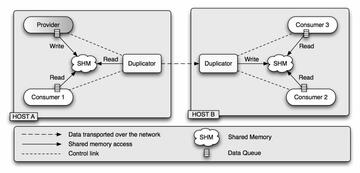
The data are transported via shared memory within a host and across the network between hosts. Multiple data copies are avoided locally and remotely.
The figure above describes a simple NDFS-II application composed of four client nodes allocated to two hosts. There is one producing client node feeding with data three consumers. The producer and one consumer run on the same host and the two remaining consumers run on an other one. On each host, a duplicator handling the flow manages the shared memory used to store data blocks and communicates with other remote duplicators if necessary.
The data is transported as follows. The producer writes a data block in the shared memory and notifies the duplicator that data are available for reading in the shared memory. The duplicator then notifies Consumer 1 running on the same host that data are available for reading in the shared memory and also sends the data block to the remote duplicator, which copies the data in the shared memory once received and notifies its consumers (Consumer 3 and Consumer 4) that data are available for reading. Once the duplicator on host A received the confirmation from Consumer 1 that it has read the data block, and also the confirmation from the duplicator on host B that every consumer on its host has also read the data, the duplicator on host A notifies the Provider that it can write a new data block in the shard memory.
Introducing the duplicator concept has several advantages. It allows concurrent reading of the shared memory within a host and avoids multiple transfers of the same data blocks via the network when several consumers are connected to the same flow on a remote host.
When a producer provides a data block to the system, this block is not sent directly but instead is en-queued in the internal flow queue of the client node. A separate thread running in the client node de-queues the data block in the background and passes it to the duplicator. Symmetrically for consumers, a thread gets data blocks from the shared memory on the duplicator signal and en-queues it in the internal flow queue. This method of transporting data avoids maintaining a reference count at the producer level and transports the data as fast as possible independently of consumers requests; therefore, when a consumer requests a new data block it could already be in the internal flow queue and available immediately. The behavior of the flow queue is customizable allowing blocking or non-blocking flows.
Language binding
The NDFS-II offers several wrappers to other programming languages. For example, a Java interface is provided allowing programs developed in Java to use the NDFS-II capabilities for data transport.
The NDFS-II is a system that allows dynamically loading of custom flows when using its C++ API. This very useful capability could not be implemented when we developed the Java wrapper for technical reasons. Therefore the Java binder is presently linked to some of our flows. These flows, Flow_Block_Test, Flow_Audio_Array and Flow_Ant_Simulation need to be built before you can use the Java wrapper. They are located in the src/flows folder of the project.
Once these flow libraries are built, the C++ side of the wrapper needs to be built using the qmake method. The sources are located in the java/smartflow2 folder.
The Java side of the wrapper does not need to be built and is already provided in the Java folder. Use this jar file when developing your Java programs to use the NDFS-II data transport capabilities.
The Java class interface located in java/smartflow2/src/org/nist/NDFS consists in the Smartflow, the Flow and Buffer classes. The prototypes of the Java classes are the same as the C++ classes.
Please refer to the How to create application section to see how to use the main objects provided by the NDFS-II API to transport your data.
The development of this wrapper was made possible by using the Java Native Interface (JNI) programming framework.
An Octave wrapper is presently in development. The prototype allows Octave programs to exchange data using the data flow capabilities within the octave scope, i.e. using Octave methods. The same concepts of the system apply to the octave wrapper, meaning that the transport is transparent for Octave client nodes. They can be running on the same machine or different hosts.
The Octave type 'cell' is used to exchange data between octave programs. An Octave data provider client node can fill out a cell with any combination of octave data types before sending it using the NDFS-II Octave methods. Using symmetrical NDFS-II Octave methods, an Octave consumer is then able to get this cell filled out with the data. The Octave wrapper is endian free, meaning that the user does not need to handle endianness when using client nodes running on different architectures.
Limitations
The NDFS-II has been developed to be a data transport medium that operates within a local area network only. It takes advantage of the gigabyte networks. Performance has always been a top-priority during the design and development of the system. Gathering data from sensors spread geographically was never a requirement. Therefore, the system does not work for applications having parts running on different networks such as the Internet. A data flow server must be on the same subnet to join an application domain because servers use a multicast request to discover each other. This request cannot go through routers, so the NDFS-II is limited to LAN networks.
Operating systems offers different capabilities. When choosing which one to use, several parameters must be weighed, including but not limited to:
- Operating systems capabilities
- Hardware support
- Third-party library support
Users can have constraints, which limit them to a particular operating system. We believe it is our role to adapt to them by providing a cross-platform middleware.
We noticed some limitations while developing multimodal application using the NDFS-II. For example, Linux appears to be the operating system having the best network throughput. We also learned that Windows XP can only handle up to 128 network connections.
Complex System simulations
The NDFS-II has been mainly designed to support research in pervasive environment. The design has however been done in a generic way as a data transport architecture allowing transport of any kind of data. We recently used the data flow in complex system simulations. A complex system is a system where there are multiple interactions between many actors or entities. The properties of a complex system are not completely explained by an understanding of its actors. Simulations are therefore required to observe and try to understand such systems.
Complex systems share some common characteristics with multimodal applications. They don't require sensors but need huge computational power. Parallelizing or distributing such applications on a cluster of computers enables faster simulation and also allows increasing the simulation size.
We simulated an Ant Colony Optimization using the data flow system. The idea is to use the collective intelligence of digital ants to find the shortest path in a graph between two nodes. By distributing the process among several computers, we sped up the runtime application of the simulation by a factor almost equals to the number of computers involved in the simulation.
The sources of this simulation are provided with the NDFS-II. The non-distributed version of the simulation has been developed in Java, so the Java wrapper of NDFS-II was used. The simulation is mainly composed of a central client node synchronizing and fusing the results of an arbitrary number of sub-processing client nodes. These sub-processing nodes have been programmed in Java, but we also have a C++ version. In our simulations, we indifferently use the Java or C++ version together, depending on the Java availability on the architectures involved.