
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
NIST Data Flow System II - User's Guide - Draft Version - Chapter 7
RETURN TO THE DOCUMENT TABLE OF CONTENTS
Table of Contents
The Control Center
-- Creating a client list
-- Creating an application map
-- Starting an application map
-- Using the discover application capability of the Control Center
-- Reading the map
-- Control Center's Hello World
The Flow Generator
The Client Descriptor
The Web Control Center
The NDFS-II is a complex system. Moreover, it is often used on clusters of machines. Some tools are provided in order to make the development and management of applications easier.
The Control Center
The Control Center is a GUI allowing one to create and manage NDFS-II applications. It gives the user the ability to build a map, i.e. to connect client nodes together and to associate each one of them to a host. Then the user can launch the application: each client node is spawned by the proper data flow server on its host.
The application can also be stopped from the Control Center. It is possible to start client nodes using the command line as well.
Once an application is started, the Control Center can be closed, the application will keep running. If the GUI is launched again, it is possible to discover the current application over the NDFS-II network and to take control of it.
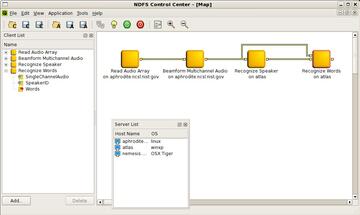
The Control Center displaying an application map composed of four client nodes.
When the Control Center is launched, it tries to connect to its local data flow server, and displays a list of servers sharing the same application domain. If no data flow server is present, you will get a warning message letting you know the Control Center cannot connect to its server. If later on you start a data flow server, you can request the Control Center to connect to the server by pressing on the
The Control Center allows one to create and manage a client nodes list. Using this list, it is then possible to create application maps. An application map describes the connection between some or all client nodes and associates each one of them with a machine from the server list.
Creating a client list: The first thing to do to create an application is to create or load a client list. A list of client nodes can be loaded from the File menu. An example file is provided in the bin/tools folder and named example_client_list.conf.
The Control Center gives you the possibility of creating a list. In order to add a client node in the list, you need to click on the "Add.." usa-button located in the client list. A dialog appears, and you can either enter manually the description file's path of a client node or select it using the "..." usa-button. For example, go to the example_consumer_memcpy's source folder and select the file example_consumer_memcpy.client file and load its description using the "Apply" usa-button.
You should get the description of the client as shown on the screenshot below.
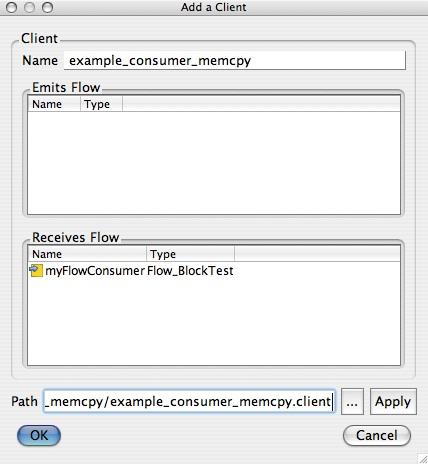
Screenshot showing the form used to add client nodes in the client list.
Validate it by clicking on the "OK" usa-button. The client node now appears in the client list. Check that the path of the client node is correct by invoking "Edit" located in the contextual menu of each client node in the list. If the path is not correct, enter the proper one. Do the same for the example_provider_memcpy client.
This list of client nodes can be saved using the File menu.
Once you have a client node list you can create an application map using them. Click on one of the clients and drag it into the map and drop it there. A dialog appears letting you select on which machine the client node should be launched. Select your current machine within the list. Drop the example_consumer_memcpy and the example_provider_memcpy in the map.
Now the two client are present in the map but not connected yet. To connect them, click on the flow outlet of one the two client nodes, drag your mouse toward the other client node and release your mouse usa-button on the outlet of the other client node.
The two client nodes are now connected. The Control Center checks that the connection is possible. If you want to connect two flow outlets, which are of different kinds, or you try to connect an output flow to an output flow, it will be refused by the Control Center.
You can save your application using from the File menu.
Note: When you save an application map, the client nodes from the list that are used in the map are also saved in the application map file. So you don't have to reload the client list corresponding to your application each time you load a map.
At this point, you created a client list and build an application map using the client nodes from the list. You can start the application by clicking on the Picture of the
Using the discover application capability of the Control Center
The Control Center is a client node, which uses special control methods provided by the NDFS-II API. So like any other client node, it can join or leave an application domain. Because this client does not provide or consume data, it does not affect your application when you shut it down. If you have an application map running, you can quit the Control Center and start it again. You will notice that the map is empty, but you can ask the Control Center to display you the application currently running in the application domain. Click on the Discover Map usa-button (
The Control Center can be really useful to monitor a NDFS II application. In order to provide an easy way to represent the status of an application in real-time, we use a color code in the map of the Control Center. Following are some screenshots showing the different states that client nodes or flow can have.
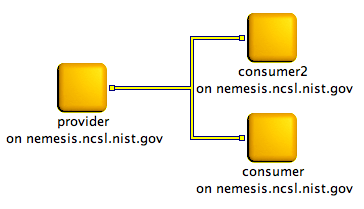
Picture showing a producer connected to two consumers. All client nodes are idle.
On this screenshot, the provider, the two consumers and the flow are in yellow. This color represents client nodes or flows, which are idle or stopped. They have either not be started yet or have been stopped.
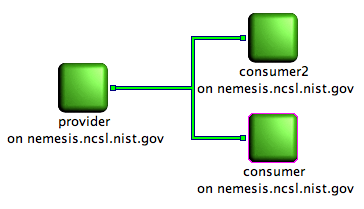
Picture showing a producer connected to two consumers. All client node are running.
On this screenshot the client nodes and the flow are green. Green means running, i.e., the client nodes have been started and the provider is sending data to the two consumers.
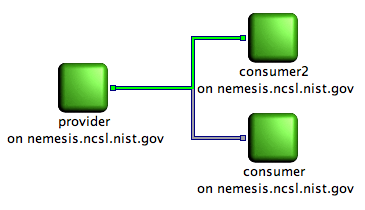
Picture showing a producer connected to two consumers. All client node are running and a consumer paused a flow.
The grey color for a flow means the flow is paused. Here consumer has paused its flow, meaning that it is still connected to the provider but the data are not send anymore to the consumer. Every piece of data sent by the provider is lost by the consumer during the time it paused its flow.
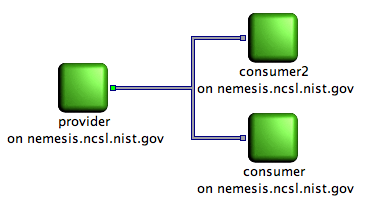
Picture showing a producer connected to two consumers. All client node are running and the provider paused a flow.
On the above diagram, either both consumers have paused the flow or the provider itself has paused. The provider is still producing data, but none of it is sent to the consumers.
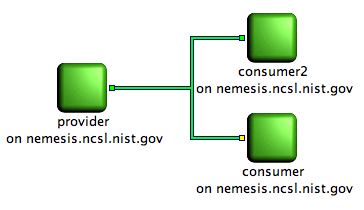
Picture showing a producer connected to two consumers. All client node are running and a consumer destroyed a flow.
On the above screenshot, all the client nodes are still running but consumer has either destroyed its flow or not created it yet. If consumer has destroyed its flow, it means it doesn't intend to consume data anymore. In order to represent this, the flow outlet of consumer is colored in yellow.
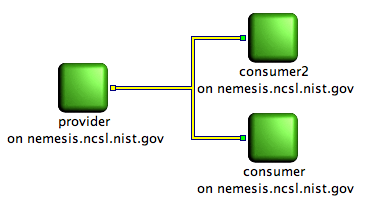
Picture showing a producer connected to two consumers. All client node are running and the producer destroyed a flow.
In the above diagram, the two consumers have been started and successfully created their input flow, but the output flow of the provider is not running. That means that the provider has not created yet its flow or has already destroyed it.
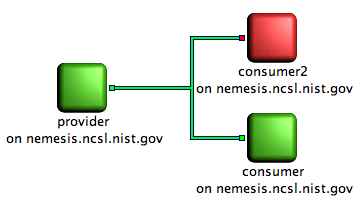
Picture showing a producer connected to two consumers. Only the provider and a consumer are running. The remaining consumer couldn't be started.
On the screenshot above, consumer2 is colored in red. That color means there was a problem starting the client node. Typically that means that the client executable has not been found.
Some client nodes, whose purpose is to provide a view of how to use the NDFS-II, are provided. This includes a client list and an example map.
The client list is located in Smartflow2/bin/clients/exampleClientList.conf and the example application map located in Smartflow2/bin/clients/exampleClientMap.app
The Flow Generator
The Flow generator is a tool accessible from the Control Center under the Tools menu. It is provided to ease the development of customs flows by creating a basic C++ skeleton of the flow. Flows within NDFS-II are implemented as shared library, meaning the core of the system does not need to be recompiled in order to include the new flow. They can be seen as plug-ins. You can use the flows provided by the system, but in many cases it is convenient to develop your own kind of flows dedicated to handle specific data types. The Control Center provides a tool to ease the creation of customs flows: the Flow Generator.
This tool will help you to create the C++ skeleton of your flow by generating the required source files needed to implement a flow. By using it, you can describe a flow, define its name, the maximum buffer size and the history size that represents the size of the internal flow queue. These 3 parameters are required in each flow. This tool also allows defining the prototype of methods specific to your flow.
Once the flow is fully described, you can save the description of the flow from the File menu, and generate the C++ code of the flow. The files generated are saved in the folder where you save the description file of the flow. Regardless of where you generate the file, we strongly encourage you to store the header file of your flow in the src/flows/Flow_YourFlow and the library once built in the lib/flows folder. It will make the development of the your client nodes easier.
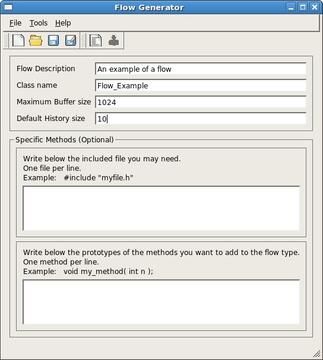
Screenshot showing the Flow Generator used to create a C++ skeleton for custom flows.
For the example above, the generated files are:
- Flow_Example.h: This is the header file of the flow and is not supposed to be edited. If you decide to edit it, be very careful when using the Flow Generator with this flow because it will regenerate the file and therefore all your modifications will be lost.
- Flow_Example.cpp: This is the implementation file of the flow. Same as above, if you generate your flow again, your modifications will be lost.
- Flow_Example_functions.cpp: This file is an implementation file containing the customs methods you have defined in the box at the bottom of the windows. It contains at least to empty methods ready to be implemented, user_init() and user_close(). These methods are respectively invoked at the creation of the flow and at the destruction. These methods are provided for convenience. If you generate the code of your flow again and this file already exists, it won't be overwritten.
- Flow_Example.pro: This file is a standard Qt project file provided to help building the shared library of the flow.
Creating a flow has several advantages: if they have been named properly it increase the visibility when monitoring applications with many flows. It is also a convenient way to perform some automatic operations on the data blocks before sending them or receiving them. One can find useful to handle endianness issues in a flow, so the client node that produces or consumes data does not have to handle it in its code. It could also be used to add metadata or interpret metadata, etc.
Let's say someone needs to transport matrices of data between client nodes. Some consuming client nodes would be interested in these matrices represented as a NxM table as it has been sent while other would prefer it to be represented as a vector of size NxM. The process of transforming the representation could be done in the client node code, it is however convenient to delegate this job to the flow itself and programming this methods only once instead of in every client node.
Basically any basic systematic processing of the data should be handle at this level. So in a client node, the only thing to do before working on the data could is to get them.
The Client Descriptor
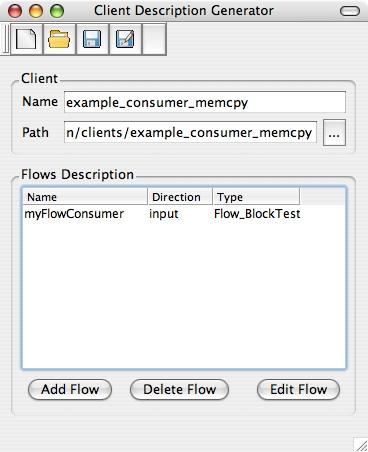
Screenshot showing the Client Descriptor tool used to generate XML description of client nodes needed by the Control Center.
The Client Descriptor, accessible from the tool menu in the Control Center, allows creating client node description files needed by the Control Center to build client lists. They basically contain information about client nodes such as name, location of the client executable, and input and output flows descriptions. A flow is described by its direction, input or output, its type and its name. The name of the flow MUST match the name used in the code of the client node when creating the flow (second parameter of the method to create flows). Otherwise the Control Center won't be able to establish dynamic connections between client nodes. This description is stored in an XML file, which can be created from scratch. However it is recommended to use the Client Description Generator to create this file in order to avoid syntax errors.
When the description process is done, you need to save the file. You can later on use this description file to declare the client node in the client list of the Control Center. Please see the How to create a client list section for more details about client node lists.
The Web Control Center
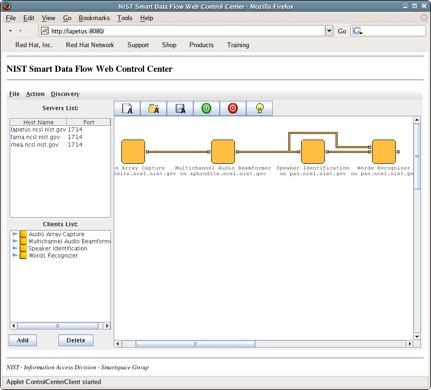
Screenshot of the Web Control Center.
A Web Control Center interface has recently been developed allowing a user to create and control NDFS-II applications from everywhere. It provides three main features.
First, you can use it to obtain a graphic representation of an existing NDFS-II application. The Web version of the Control Center also implements the application discovery capability. Second, the applet provides control to the user over an existing application. Thereby, you can start and stop all clients or only some of them.
Finally, the web interface allows one to build NDFS-II application. It is possible to allocate client nodes to hosts, connect these clients together through flows and start or stop the application or part of it. A description of application graphs (or map) can be saved for future reload.
The web interface is less complex than the C++ Control Center. But the C++ Control Center needs to be on a machine with a running NDFS-II server in order to take control of an application. The applet is running within a Web browser and has no need for a data flow server to be launched on the local host. It works well on every platform (Windows, Linux, Mac OS X...), only a web browser with the Java plugin is required.