
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
Trusted Computations from Terabyte-sized Images Using Cluster and Cloud Computing with the Web Image Processing Pipeline (WIPP)
Summary
High-end automated microscopes can acquire very large volumes of data, reaching into terabyte territory. These data volumes impose their own constraints. They necessitate the reuse of image collections from expensive experiments as well as the use of complex analytical tools running on high-performance computing (HPC) resources to minimize the waiting times for image processing and enable data-driven discoveries. There is a need to assist imaging scientists with computational solutions that make (a) the use of HPC resources easy, (b) large image collections searchable and accessible, (c) data processing tools reusable and interoperable so that complex workflows of processing steps can be created.
To address these needs, we designed a web image processing pipeline (WIPP) client-server system for constructing and executing computational workflows, monitoring executions and gathering provenance information, and delivering traceable results of computations. In addition, we have introduced interoperable interfaces for containerized image processing tools in order to chain them into workflows and registering them as plugins in the WIPP system. We also deployed a registry of plugins so that users can perform a federated search over all registries to find plugins (processing tools) of interest.
Description
The goal of this project is to lower the bar for users and algorithm developers to execute and share image analyses over terabyte-sized image collections in high-throughput and high content microscopy imaging applications.
- Upload collections of microscopy images,
- Register algorithmic plugins,
- Configure image processing workflows,
- Stitch grids of small fields of view,
- Visualize and analyze large fields of view interactively using the pyramid view,
- Extract image features and customize scatterplots,
- Train and use Tensorflow models for image segmentation, regression and classification,
- Prototype algorithms with polyglot Jupyter notebooks.
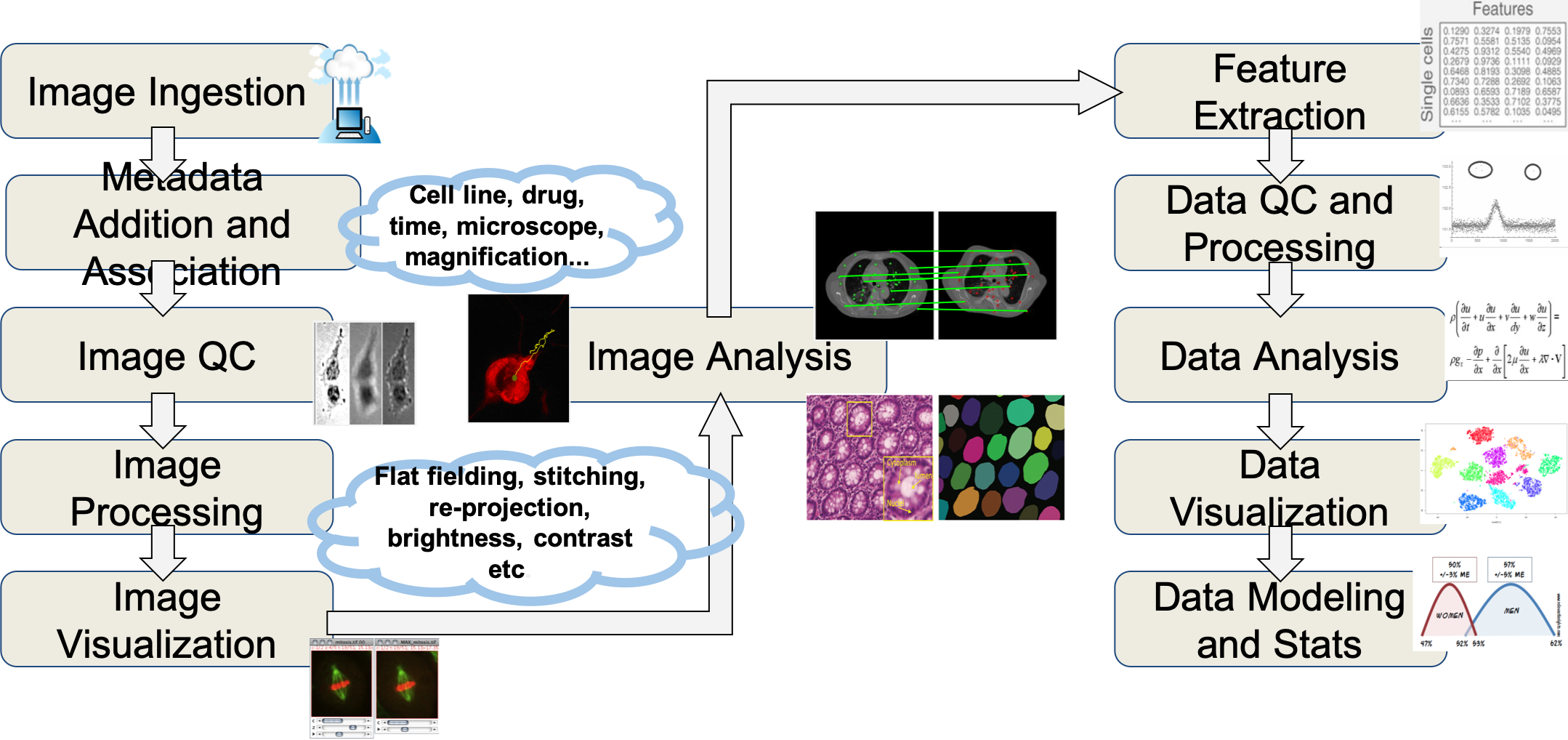
WIPP is designed as an expandable platform leveraging containerization and orchestration technologies such as Docker and Kubernetes and is meant to be deployed on a Kubernetes cluster (see Installation instructions).
The core of the WIPP framework consists of:
- the WIPP REST API, based on the Java Spring framework,
- the WIPP web UI, an Angular application,
- a MongoDB database,
- Keycloak, an open source identity and access management server,
- Argo Workflows, a container native workflow engine for Kubernetes,
- WIPP Plugins, algorithmic plugins packaged as Docker images.
Additional tools can be added to the WIPP core for a more complete system:
- JupyterHub, to develop polyglot Jupyter notebooks that can be used in WIPP workflows,
- Plots, for scalable and interactive scatterplots visualization,
- Tensorboard, for Tensorflow jobs monitoring,
- Elastic Stack for application, logs and system monitoring.
Major Accomplishments
The main accomplishments include:
- access and traceability of computations over terabyte-sized image collections executed in cluster and cloud HPC environments so that computational results can be reproduced,
- introduction of interoperable containerized software tools/plugins so that complex software can be reused, and
- deployment of plugin registries so that plugins of interest can be found via a federated search.
Associated Product(s)
Resources/Demos
Description:
Software pointers:
Source code:
WIPP plugin registry:
- Website: https://wipp-plugins.nist.gov
- Source code and deployment instructions: https://github.com/usnistgov/WIPP-Registry