
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
In April 2026, the Center for AI Standards and Innovation (CAISI) evaluated the open-weight AI model DeepSeek V4 Pro (“DeepSeek V4”). CAISI evaluations indicate that DeepSeek V4’s capabilities lag behind the frontier by about 8 months (Figure 1).
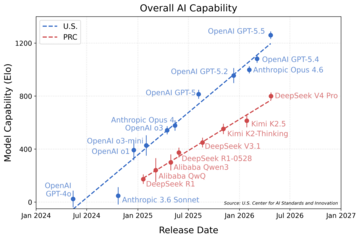
Figure 1: Comparison of aggregate capabilities over time of the most capable publicly released U.S. and PRC models according to a suite of benchmarks covering five domains.
Every 200-point increase on the y-axis equates to a 3x increase in the odds of solving a given task. Model capability was fitted using an approach inspired by Item Response Theory (IRT), as detailed in the Appendix. 16 benchmarks across 35 models were used to produce this figure. Trend lines were fit with least squares regression on frontier models. Error bars denote 95% CIs.
Key Findings
- DeepSeek V4 is the most capable PRC AI model evaluated by CAISI to date. CAISI evaluations span the domains of cyber, software engineering, natural sciences, abstract reasoning, and mathematics (Figure 2).
- DeepSeek V4 scores better on DeepSeek’s self-reported evaluations than on CAISI evaluations. According to DeepSeek’s data, DeepSeek V4 is about as capable as Opus 4.6 and GPT-5.4, which were released about 2 months ago. However, CAISI’s evaluations, which include non-public benchmarks, indicate that DeepSeek V4 performs similarly to GPT-5, which was released about 8 months ago (Figure 3).
- DeepSeek V4 is more cost efficient than other models of similar capability. Compared to the most cost-competitive U.S. reference model (GPT-5.4 mini), DeepSeek V4 was more cost efficient on 5 out of 7 benchmarks. On the 7 benchmarks, DeepSeek V4 ranged from 53% less expensive to 41% more expensive.
Capability Results
- DeepSeek V4’s capability lags behind leading U.S. models by about 8 months (Figure 1). The methodology applied can be found in the Appendix.
- DeepSeek V4 is the most capable PRC model to date across the domains that CAISI evaluated: cyber, software engineering, natural sciences, abstract reasoning, and mathematics. CAISI evaluated models on nine benchmarks across these five domains, including two held-out and uncontaminated benchmarks: ARC-AGI-2’s semi-private dataset, and CAISI’s internally-built software engineering evaluation PortBench.
Domain | Benchmark | Model (reasoning level) | |||
OpenAI GPT-5.5 | OpenAI GPT-5.4 mini | Anthropic Opus 4.6 | DeepSeek V4 Pro | ||
Cyber | CTF-Archive-Diamond | 71% | 32% | 46% | 32%*** |
Software Engineering | SWE-Bench Verified* | 81% | 73% | 79% | 74% |
PortBench | 78% | 41% | 60% | 44% | |
Natural Sciences | FrontierScience | 79% | 74% | 72% | 74% |
GPQA-Diamond | 96% | 87% | 91% | 90% | |
Abstract Reasoning | ARC-AGI-2 semi-private** | 79% | – | 63% | 46% |
Mathematics | OTIS-AIME-2025 | 100% | 90% | 92% | 97% |
PUMaC 2024 | 96% | 93% | 95% | 96% | |
SMT 2025 | 99% | 92% | 94% | 96% | |
IRT-Estimated Elo | 1260 ± 28 | 749 ± 46 | 999 ± 27 | 800 ± 28 | |
Figure 2: Summary of model performance per capability benchmark (higher is better).
Results show accuracy (percentage of tasks solved) on each benchmark. For each benchmark, the top-performing model is highlighted and bolded. IRT-estimated Elo uncertainties reflect a 95% confidence interval. *CAISI scores on SWE-Bench Verified tend to be lower than those of other evaluators, likely due to system prompt, scaffolding, and token budget differences. **CAISI reports mean score across tasks, which differs from ARC-AGI-2’s official score aggregation methodology. ***Imputed from a subset of samples via IRT.
Benchmarks
This evaluation used the following benchmarks:
- ARC-AGI-2 Semi-Private: a non-public dataset measuring abstract reasoning from the ARC Prize Foundation. "Semi-Private" means these tasks may have been exposed to limited third-parties.
- CTF-Archive-Diamond: a CAISI-developed benchmark based on 285 difficult CTF challenges drawn from the pwn.challenge cybersecurity platform developed by Arizona State University.
- PortBench: a CAISI-developed non-public evaluation that assesses the ability of AI models to port command line interface (CLI) tools to different programming languages, given a reference implementation in one language. CAISI plans to release an in-depth description of PortBench in the future.
- FrontierScience: a benchmark that evaluates expert-level scientific reasoning through international science olympiad problems and PhD-level, open-ended problems representative of sub-tasks in scientific research in physics, chemistry, and biology, developed by OpenAI.
- For descriptions of the other benchmarks, see Section 3 of CAISI’s earlier Evaluation of DeepSeek AI Models.
Capability Lag Measurement
CAISI uses an approach inspired by Item Response Theory (IRT) to determine the capability level of each evaluated model aggregated across the evaluated benchmarks. IRT was originally developed for psychometric testing, such as a setting where a group of students complete a number of exam questions, and the results are used to determine the relative competency of each student and the difficulty of each exam question. CAISI applies a similar technique for aggregate capability measurement by treating AI models as students and individual benchmark tasks as exam questions. For a fuller explanation, see the Appendix. As shown in Figure 1, the U.S. capability frontier tends to lead the PRC frontier by roughly 8 months.
Model Serving and Inference
CAISI served DeepSeek V4 from cloud-based H200 and B200 GPUs, and used developer-recommended settings for context length, max_tokens, temperature, top_p, preserving internal reasoning, system prompt, and maximum thinking. To rule out the presence of inference or configuration errors, CAISI reproduced the developer’s self-reported benchmark results on GPQA-Diamond.
Agentic evaluations were conducted with Inspect’s built-in ReAct agent. Budgets were set to 1M weighted tokens for PortBench and CTF-Archive-Diamond, and 500k weighted tokens for SWE-Bench Verified. For the definition of weighted tokens, see Appendix A2 of CAISI’s earlier Evaluation of DeepSeek AI Models.
Comparison of DeepSeek and CAISI Evaluations
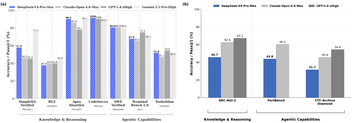
Figure 3: Comparison of DeepSeek V4 with frontier US models across two benchmark suites.
(a) Benchmarks selected and reported by DeepSeek, where V4 appears roughly on par with frontier US models. (b) Benchmarks from CAISI’s suite on which DeepSeek V4 lags behind U.S. models. CAISI pre-committed to its overall benchmark suite, i.e. did not select benchmarks on the basis of results.
DeepSeek's technical report indicates DeepSeek V4 is competitive with frontier U.S. models across a range of benchmarks (Figure 3a). However, CAISI’s evaluation of these models on benchmarks not featured in DeepSeek's report show worse performance on some reasoning and agent-based evaluations, like the ARC-AGI-2 semi-private dataset, the held-out software engineering evaluation PortBench, and the cyber benchmark CTF-Archive-Diamond (Figure 3b).
DeepSeek V4 Costs Less Than Other Models Of Similar Capability
For the purpose of cost comparison, CAISI selected a U.S. reference model by filtering out U.S. models that performed significantly worse on public benchmarks or that cost significantly more per token than DeepSeek V4 Pro. The only model meeting these criteria was GPT-5.4 mini, which was selected as a point of reference. In CAISI’s aggregated capability analysis, GPT-5.4 mini receives an Elo score of 749, which is similar to DeepSeek V4 Pro’s score of 800.
DeepSeek V4 costs less than GPT-5.4 mini on 5 out of 7 CAISI benchmarks. On those 7 benchmarks, DeepSeek V4 ranged from 53% less expensive to 41% more expensive. Two CAISI benchmarks were excluded from cost comparisons: PortBench because it has continuous scoring which isn’t yet supported by CAISI’s cost comparison methodology, and ARC-AGI-2 because of technical issues with the GPT-5.4 mini evaluation run.
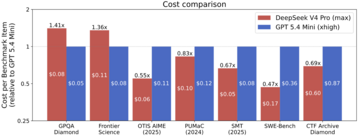
Figure 4: End-to-end expense of GPT-5.4 mini and DeepSeek V4 Pro on different benchmarks, for benchmark tasks that both models solve correctly.
Taller bars represent higher end-to-end cost. Values above 1.0 indicate DeepSeek V4 costs more than GPT-5.4 mini. Numbers within the bars denote the average expense a model incurred to solve a benchmark task/question (where the average is computed over the set of benchmark tasks/questions that both models solve correctly).
The following developer-reported token prices were used:
| Input token cost (uncached) | Input token cost (with cache) | Output token cost |
DeepSeek V4 Pro | $1.74 / 1M tokens | $0.0145 / 1M tokens | $3.48 / 1M tokens |
GPT-5.4 mini | $0.75 / 1M tokens | $0.075 / 1M tokens | $4.50 / 1M tokens |
Appendix
An approach inspired by Item Response Theory (IRT) can be used to model the setting in which multiple students (AI models) each answer a series of exam questions (benchmark questions/tasks) and responses are scored as “correct” or “incorrect”. CAISI chose to use the 1PL variant of IRT due to its simplicity and strong predictive performance. Under this variant:
- Each LLM i has a latent capability level θi
- Each benchmark question/task j has a latent difficulty level δj
- If an LLM with capability θi attempts a question with difficulty δj, they succeed with probability pij = σ(θi - δj )
Given a matrix of models and benchmark question/task scores, CAISI fit a 1PL IRT statistical model and obtained the best fits for each model’s latent capability level θi, which were then used to create Figure 1. When fitting the model, equal weight was given to each benchmark within a domain, and equal weight was given to each of the five evaluation domains. CAISI controlled weighted token budgets and agent scaffolding across all benchmarks to ensure comparability. CAISI plans to release a more in-depth writeup of the methodology in the near future.