
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
Taking Measure
Just a Standard Blog

Michael Brundage using a coordinate-measurement machine in the Manufacturing Systems Integration Laboratory, a component of the Smart Manufacturing Systems (SMS) Test Bed.
“How do we get smart?” I was first asked this question while sitting in on a call with a small manufacturer who supplied parts for automotive manufacturers. With all the buzz around “smart manufacturing,” this manufacturer wanted to join the movement. The problem was that its leaders didn’t know where to start. They bought sensors without any real understanding of what to do with them. When I asked why, they said they didn’t have any useful data and they needed data to be “smart.” I asked them, “How do you not have any useful data?” They said they only had documents capturing the history of each maintenance event in the facility. These “textual maintenance work orders” were hardly useful due to their unstructured, jargon-filled nature. At the time they were right; this data in its natural form seemed useless.
However, when my colleagues and I in the Knowledge Extraction and Application for Manufacturing Operations project manually analyzed the data, we discovered a treasure trove of hidden information. Hydraulic leaks had occurred more than 40 times in three months, but they were going unnoticed because technicians wrote down “hyd leak” or “hydraulics were leaking” or “hydaurlic (sic) burst and leak.” They were not noticing that a maintenance technician only worked on cleaning the base of a machine because they wrote down “clean base,” “base clean,” or “cleaned base.”
After we presented this information to the company's leaders, they realized they had the data to become “smart,” but they still could not perform the analysis. After we spoke with other manufacturers, both big and small, and with other experts across various industries from mining to heating, ventilation, and air conditioning (HVAC), we realized this problem of obtaining value from maintenance work orders (MWOs) was ubiquitous.
Enter NIST
First, we needed to find out why there were so many people describing the same thing so differently. We performed an experiment: We had multiple NIST manufacturing experts describe what happened in this highly viewed clip of a machine-shop mishap.

How would you describe what is happening here? Does your version match the NIST experts?
Expert 1: The cutting tool snapped off. Need to replace tool and inspect spindle for damage. Looks like they were cutting too deep in one pass for the strength of the tool.
Expert 2: The depth of cut (DOC) is too large and the feed too high for the slot such that the forces increase until tool breakage as the tool approaches the vise. It probably wasn’t smart either to machine towards the vise as they have anyway. A typical approach to avoid this problem is to ramp into the slot.
Expert 3: All-around operator error. Looks to be too high a depth of cut at too high a feed-rate. Also looks like the move at the end put too high a stress on the tool. Operator should have retracted the tool before making that move if he/she wanted to keep that depth of cut.
Expert 4: Too large of an engagement at too high of a feed.
What do you notice here? Four very different descriptions! Some of their diagnoses were longer, some shorter, some with abbreviations, some with jargon, some with shorthand, others with full sentences, but still some commonalities between them. Now imagine describing this problem two hours, four hours, or eight hours later at the end of your shift as a technician! The descriptions might be even more different. This is the problem that maintenance technicians face on a day-to-day basis.
So how do we make it easier on the technicians while still finding the patterns between the descriptions? Let’s start by looking at the commonalities between the descriptions of the video.
Most said that the “tool is broken”; others said that the “depth of cut (DOC) is too large” or that the “feed rate is too high”; some describe the “bad process plan” and the overall “operator error.” Knowing that these commonalities exist, can we just force the technician to use a pre-populated problem code (a drop-down menu)? Well, let’s try that. Which of these potential problem codes make the most sense for this video?
- Broken CNC*
- Poor planning
- CNC is broken
- Broken tool
- High depth of cut
- Error by operator
- Miscellaneous
- Too high of feed rate
- Operator error
- Broken machine tool
- Poor process planning
- Other
- Broken end mill
- Technician error
- M2 is broken
- Broken drill
- Mike!!!
- Milling machine down
- Problem code 083AM
- Power supply problem
- Broken drill tip
- Part planning is bad
- Design error
- N/A
It’s really hard to find the correct one, if there even is one. Now imagine you have to run to another machine failure and need to do this quickly. Most technicians just select “other” and write down what’s wrong because it is quicker and they are getting paid to fix problems, not write down good data. This leads to the problems we described above. So instead of using a drop-down menu, what if we parse through the descriptions written down by the technicians using natural language processing (NLP)? Here, a computer interprets and organizes natural language, like all the various errors described above, and turns it into useful, actionable data. Possible Solutions What would some solutions look like? Well, we could go through manually, work order by work order and determine the “cause,” “effect” and “solution” for each problem, as shown here.
| Work Order Data | Cause | Effect | Solution |
| HP coolant pressure at 75 psi. Bad gauge/low-pressure lines cleaned ou (sic) | Broken gauge | Low coolant pressure | Cleaned out low-pressure lines |
While this certainly brings more structure to the data, it is still time-consuming and can be inconsistent. If the same person sees “bad gauge” on the thousandth work order, will they remember to put “broken gauge”? Adding to this, it takes a lot of time and cognitive effort to think of which portion of the original data is the cause and which portion is the effect (was “broken gauge” the cause or effect in this scenario?). In fact, when one person tried to annotate the data, annotating 800 work orders took 12 hours!
We could also potentially use this manually annotated “cause,” “effect” and “solution” as training data for a machine learning model. While this certainly is possible, it would require much more than 800 annotated work orders, which takes more annotators and much more time and might be impossible depending on your problem and budget.
Now, one of the problems in the above method is the amount of effort it takes to determine the “cause,” “effect” and “solution.” In the example above, is the “bad gauge” the “cause” or “effect”? Figuring this out is difficult for an annotator, so what if we changed what we wanted the clean data to look like? What if instead of identifying the “cause,” “effect” and “solution,” the annotator simply identifies words as “items,” “problems” and “solutions”? This “tagging” paradigm is simpler for an annotator because most words in the MWOs are mutually independent, e.g. “replace” is almost always a “solution,” whereas “gear” is almost always an “item.” So, what does this look like?
| Work Order Data | Items | Problems | Solutions |
| HP coolant pressure at 75 psi. Bad gauge/low-pressure lines cleaned ou (sic) | High-pressure coolant, gauge, low-pressure lines | Broken, low pressure | Cleaned out |
Using this process, one person manually annotated 1,200 MWOs in 12 hours: a marginal improvement.
Since manually annotating one work order at a time takes an extraordinary amount of time and effort, what if instead we leveraged natural language processing to analyze the entire set of MWOs at once? NLP methods can extract and rank all the words, which we call tokens, from the raw text throughout all of the MWOs and then present them to a human annotator to classify into “items,” “problems” and “solutions” (we also include “irrelevant” and “unknown” classifications). This approach takes advantage of both the strengths of NLP and human expertise. So, what does this look like?
1) Extract Tokens From MWOs
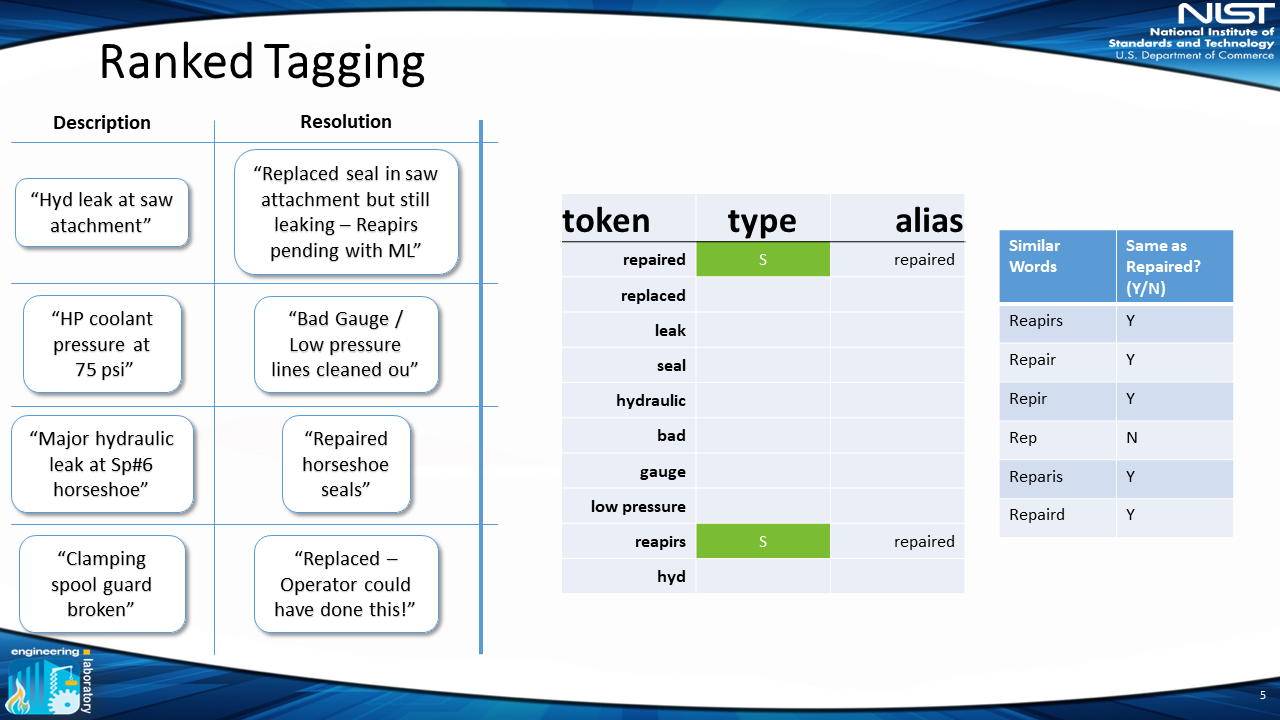
First, we start with the raw data — in this example, the data has a description and resolution field:
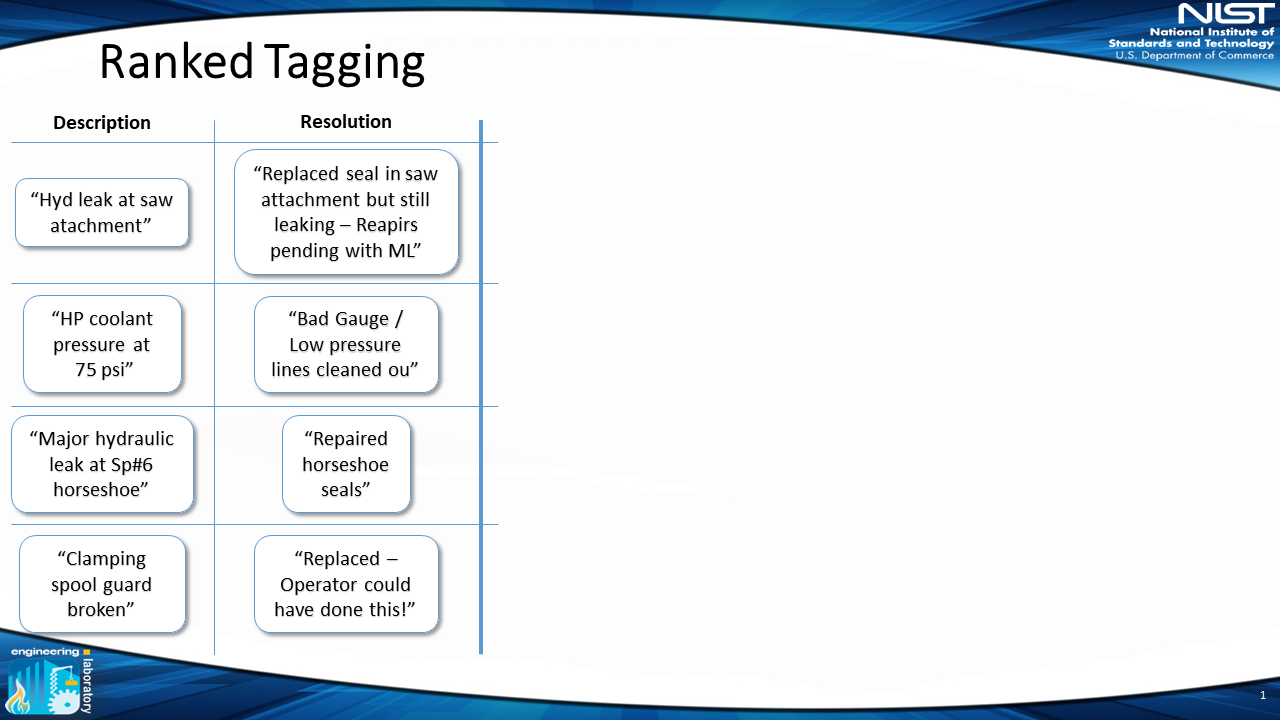
2) Rank Tokens
Next, we look at the tokens across all the work orders. These tokens are automatically ranked in order of importance. As you can see, the tokens include misspellings, abbreviations and jargon. This is because the tokens are pulled from the raw text.
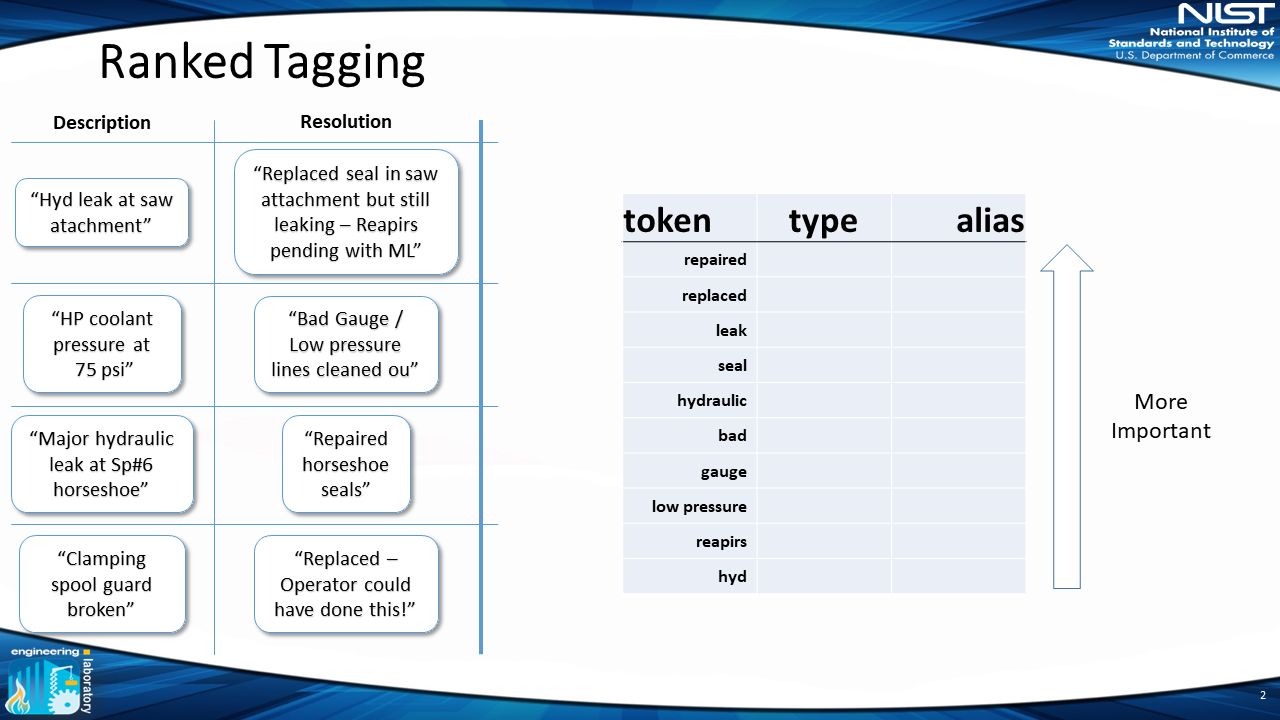
3) Select Similar Words
Once these words are presented to a user in order, the user is presented with similar words from other inputted work orders. The user can then analyze words of similar spelling. This step takes advantage of the computer’s ability to quickly identify potential similar words, but also uses a human’s ability to understand and determine what words are actually the same.
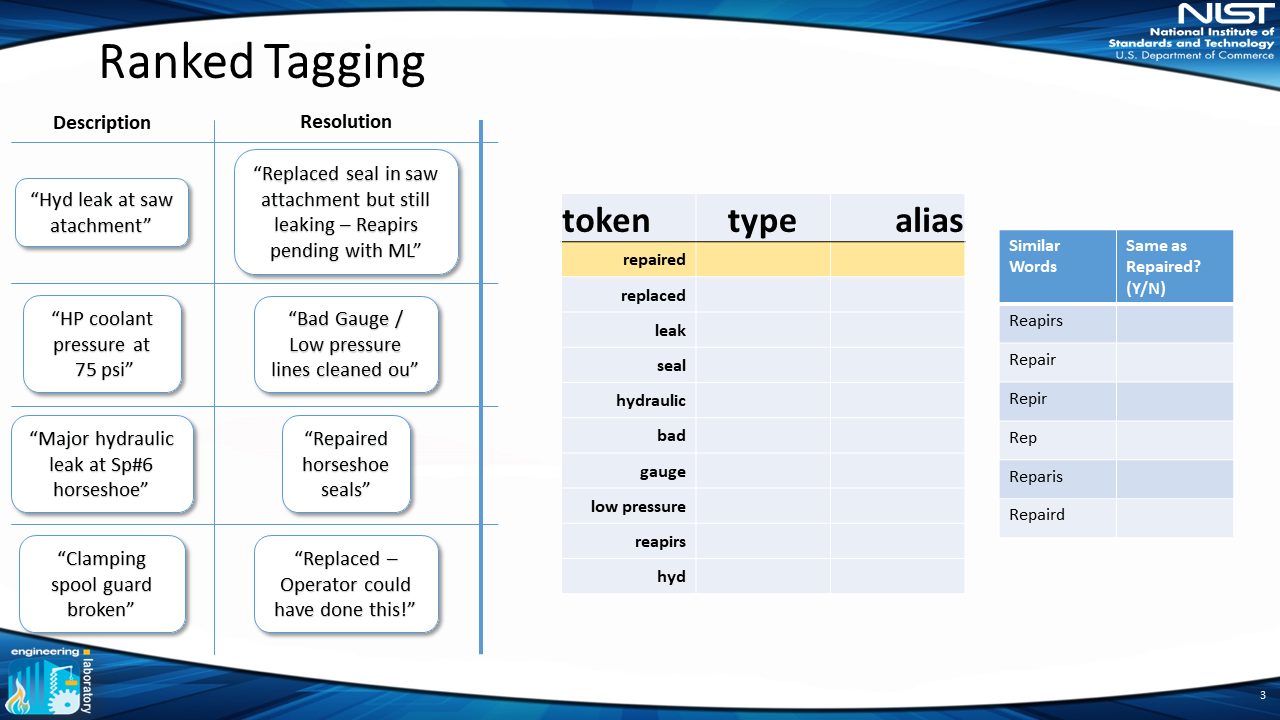
In this example, "rep" might mean "repaired" or "replace," thus the user selects only "repaired = reapirs = repair = repir = reparis = repaird."
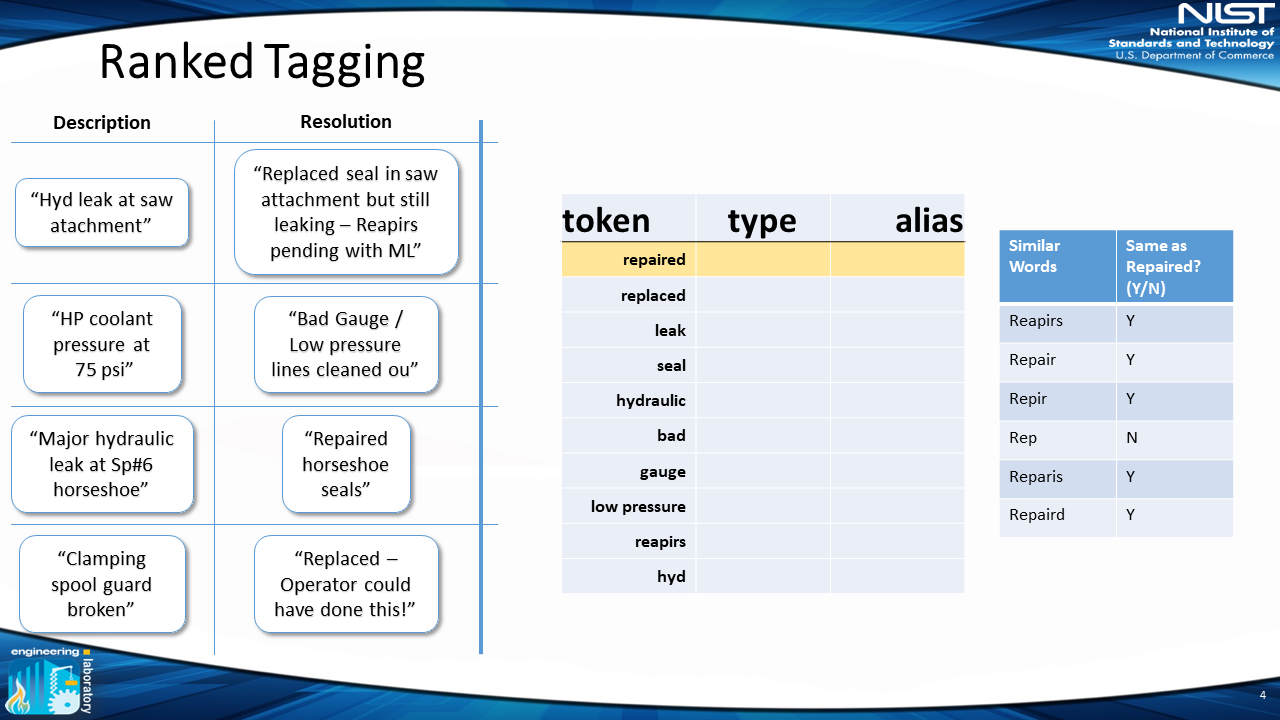
4) Create Preferred Alias
After determining similar words, the user can now determine the proper “alias” for the term — in this example: “repaired” — and the “classification” of that word.
5) Determine Word Type
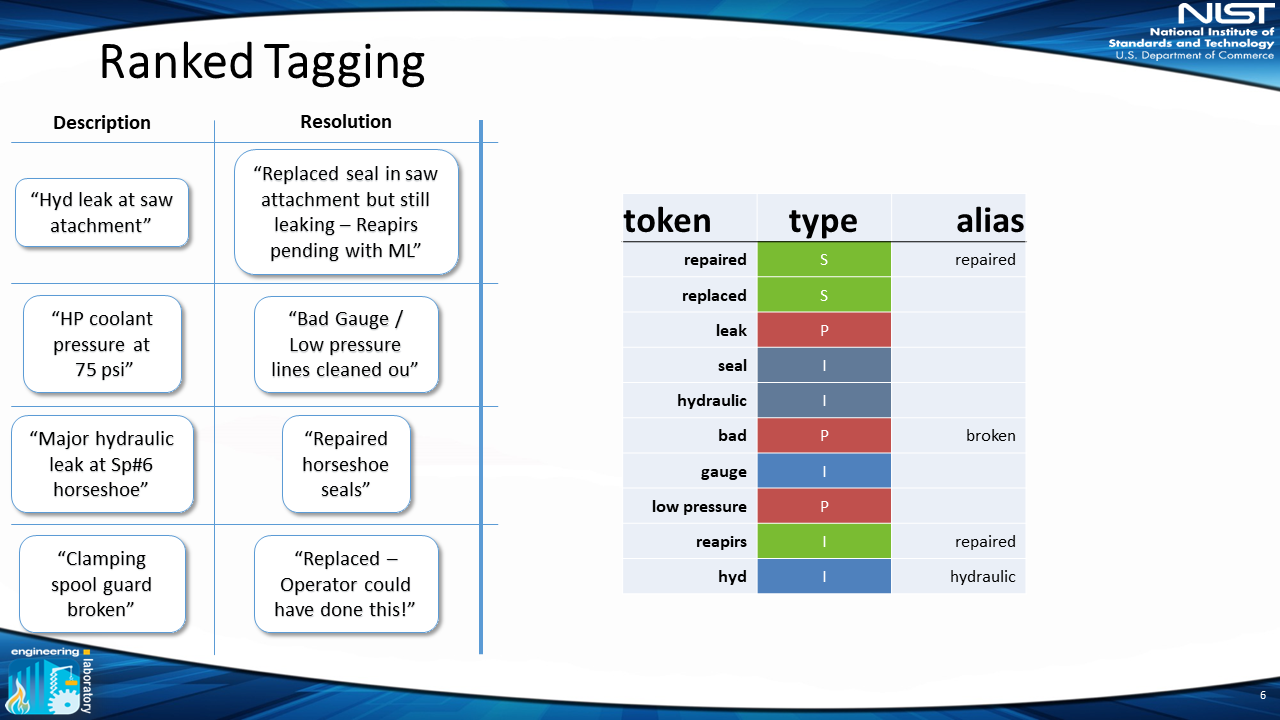
For the classification, we use “items,” “problem actions” and “solution actions,” “irrelevant” (terms that are not important for analysis, e.g. “this,” “that”) and “ambiguous” (terms that are unclear with only one word, e.g. “hot” could mean “too hot,” which is a problem, or “hot water,” which is an item). This allows the user to classify a token as one of those five classes. In this example, “repaired” is a “solution” (indicated by the green “S” in the figure).
The user can then perform this same process for more tokens. As opposed to a drop-down menu with a limited set of terms, the advantage of this system is the ability of the user to perform this process on as many tokens as they want. Since the tokens are ranked in terms of importance, the user can annotate a lot of work orders quickly, as words like “repaired” occur much more frequently than words like “asset145.” This allows for a large return on investment where a small amount of time classifying tokens leads to a large amount of annotated work orders.
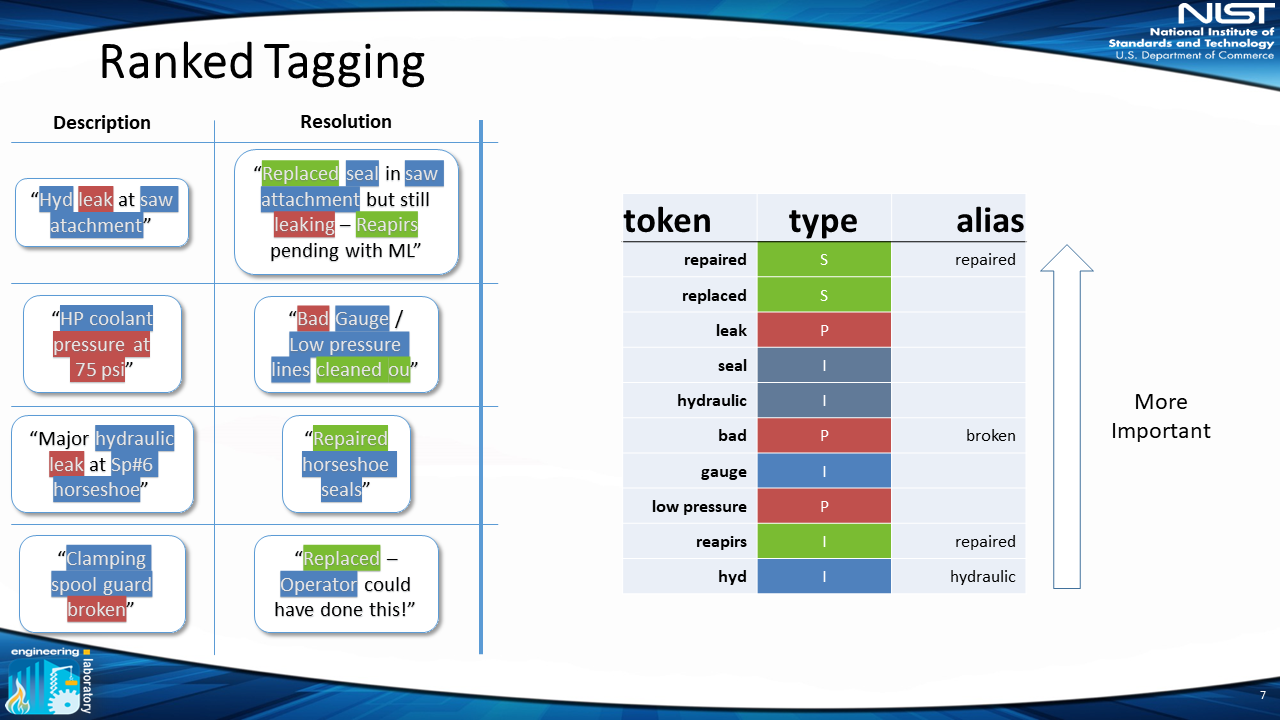
6) Automatically Annotate MWOs
Once this process is completed, each individual MWO is automatically tagged with the words that appear in each work order, according to their classification and alias.
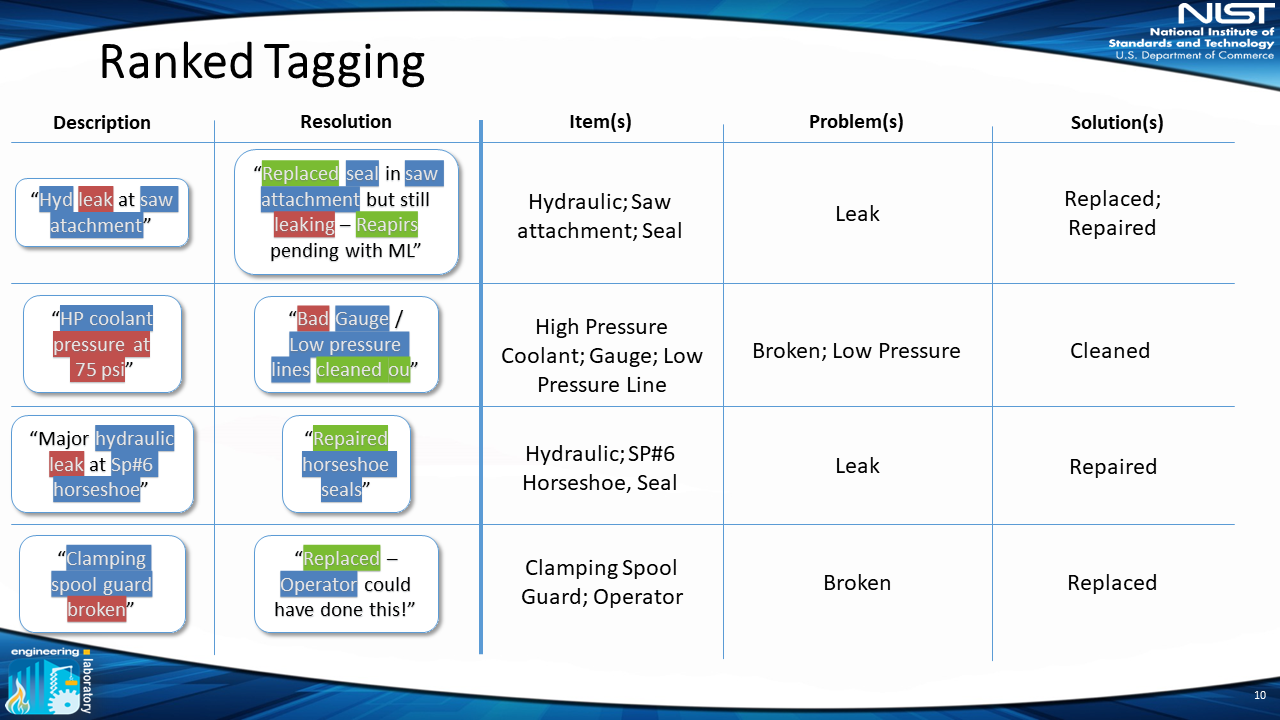
Now the work orders will have the “items,” “problem actions” and “solution actions” that occur in each work order. The “irrelevant” terms and “unknown” terms will be recorded as well.
Using this methodology on the same data set as described above, a user spent 45 minutes merging similar words, classifying those words, and creating aliases. Using the same dataset in which it took 12 hours to fully manually tag 1,200 MWOs, this system allowed for 3,300 MWOs to be fully tagged. Out of the remaining 2,200, 2,000 had some tags associated with them. A huge improvement from the other methods described!
To help manufacturers utilize this method, the NIST team developed a free, open-source application called Nestor. We have been working with manufacturers, both large and small, to pilot this method, perform case studies, and create reproducible decision workflows.
We also recently held a workshop where we had more than 25 participants from industry, government and academia, to discuss the current trends, successes, challenges and needs with respect to natural language document analysis for decision support in manufacturing and further the work of a critical manufacturing standards community to produce publicly available guidelines for industry. We are actively working on a report documenting the results, which will be out in 2020.
Lastly, we produced a state-of-the-art paper for both ASME Manufacturing Science and Engineering Conference (MSEC) and ASME Journal of Manufacturing Science and Engineering (JMSE) to tackle the problem of where to start a smart manufacturing journey. The paper, titled “Where do we start? Guidance for technology implementation in maintenance management for manufacturing” is available on the NIST website.
Next Steps
Further pilots with industry to create reproducible case studies are needed to allow manufacturers to implement this method in their decision workflows for analysis of their work orders.
Reference datasets need to be produced to allow researchers to test and validate their work on a common dataset. Some work has been done by the University of Western Australia with mining excavator data, but more is needed. Following the success of the workshop, there is a lot of buzz about creating a community of interest around this work to further the field of natural language processing in the maintenance community. This community of interest will be started in FY20. In the interim, some of this work is being investigated by the ASME Standards Subcommittee on Advanced Monitoring, Diagnostics, and Prognostics for Manufacturing Operations.
We hope that this work and the work of other researchers can help manufacturers and other maintainers improve their decision-making process to further help them get “smart.” If you have interest in any of these activities, please leave a comment!
* computerized numerical control
About the author

Related Posts



Comments
Do you think this process could be applied to establish standards and error rates for test methods/protocols for the positive identification of controlled substances?
Thanks
Hi Mike - this is along a similar path as I’ve taken with my Excel-based search engine. Let’s take some time to see your development soon.
Jeff