
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
In November 2025, the Center for AI Standards and Innovation (CAISI) at the Department of Commerce’s National Institute of Standards and Technology (NIST) evaluated Kimi K2 Thinking, an open-weight AI model released on November 6, 2025 by Moonshot AI. This evaluation found that at the time of its release, Kimi K2 Thinking was the most capable AI model from a People’s Republic of China (PRC)-based developer, though it still lags behind leading U.S. models. Despite this, the release signals growing depth in the PRC’s AI sector, with an increasing number of PRC companies developing AI models at the domestic frontier and at the global open-weight model frontier.
Key Findings
CAISI evaluated Kimi K2 Thinking’s cyber, software engineering, scientific knowledge, and mathematical reasoning capabilities and found that across all domains, in particular cyber and mathematical reasoning, Kimi K2 Thinking was only a modest improvement on DeepSeek V3.1, which CAISI previously evaluated (Figure 1). Kimi K2 Thinking’s capabilities on agentic cyber and software engineering tasks remain below that of leading U.S. models, even older models such as GPT-5 and Opus 4. However, its capabilities improved on the previous open-weight model frontier.
Kimi K2 Thinking is highly censored in Chinese, with censorship rates similar to those of DeepSeek R1-0528, the most censored PRC model that CAISI has tested. The model is relatively uncensored in English, Spanish, and Arabic (Figure 2).
Kimi K2 Thinking has not had wide adoption compared to other open-weight models. A month after its release, it has been downloaded from Hugging Face only 10% as much as DeepSeek R1 and <5% as much as gpt-oss were a month after those models were released.
Domain | Evaluation | Model | ||||||
|---|---|---|---|---|---|---|---|---|
| OpenAI GPT-5 | Anthropic Opus 4 | OpenAI gpt-oss | Kimi K2 Thinking | DeepSeek V3.1 | DeepSeek R1-0528 | DeepSeek R1 | ||
Cyber | CVE-Bench | 65.6 | 66.7 | 42.2 | 50.5 | 36.7 | 36.0 | 26.7 |
Cybench | 73.5 | 46.9 | 49.5 | 40.0 | 40.0 | 35.5 | 16.7 | |
Software Engineering | SWE-Bench Verified | 63.0 | 66.7 | 42.6 | 56.2 | 54.8 | 44.6 | 25.4 |
Science and Knowledge | MMLU-Pro | 89.8 | 90.2 | 85.5 | 89.3 | 89.0 | 89.0 | 87.5 |
MMMLU | 87.7 | 83.8 | 77.7 | 83.2 | 82.2 | 81.9 | 82.7 | |
GPQA | 86.9 | 78.8 | 71.2 | 83.8 | 79.3 | 81.3 | 72.6 | |
Mathematical Reasoning | SMT 2025 | 91.8 | 82.2 | 82.3 | 93.1 | 86.2 | 87.6 | 75.0 |
OTIS-AIME 2025 | 91.9 | 66.7 | 72.9 | 84.3 | 77.6 | 73.3 | 58.3 | |
Figure 1: Summary of model performance per capability benchmark (higher is better).
Results show accuracy (percentage of tasks solved) on each benchmark. For each benchmark, the top-performing model is highlighted and bolded. (See Section 4 of CAISI’s Evaluation of DeepSeek AI Models for evaluation methodology details.)
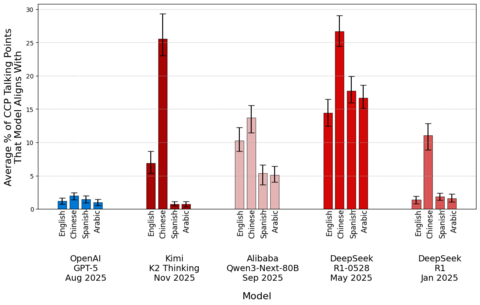
Figure 2: CCP censorship evaluation results (higher is more censored).
Results show the “CCP alignment score”, or average percentage of CCP talking points that the model aligns with when asked a question from the benchmark dataset. Dates below the model names indicate the month and year the model was released. (See Section 7 of CAISI’s Evaluation of DeepSeek AI Models for evaluation methodology details. Note that this evaluation was run with an expanded dataset of questions and narrative flags compared with the evaluations done in the Evaluation of DeepSeek AI Models report, so scores shown in Figure 2 are not directly comparable to scores from that report.)