
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
For the most up to date information, please visit our tlp-coi [at] nist.gov (Slack Channel) and our GIT homepage! You can also find a variety of resources there including a link to a free text processing learning course
Mission Statement:
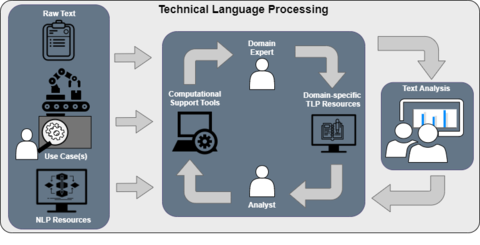
NIST has established the Technical Language Processing Community of Interest (TLP COI) to help bridge the gap between between AI-assisted Natural Language Processing (NLP) and technical, engineering, and industrial applications by providing best practice methods and tools to develop, adapt, and evaluate systems utilizing human-generated language in technical domains.
Scoping Goals:
- Create a welcoming collaborative environment to encourage and enable the connection and collaboration of different efforts and stakeholders
- Stakeholders from industry, government, and academia all share interest in the area of human machine interaction and technical language processing - we will provide space and events for connections to form, grow, and produce top quality efforts to push forward the domain of TLP.
- Develop community driven standards and best practice recommendations for creating, evaluating, and deploying TLP tools and solutions
- Tools and algorithms must be tailored for, accessible to, and usable by users and relevant stakeholders without extensive auxiliary knowledge of AI or language processing.
- Capture and outline industry challenges
- Technical and industrial applications have unique restraints, requirements, and resources that must be accounted for in designing solutions to those challenges.
- Foster community generation and curation of communal datasets that facilitate industry innovation and collaboration
- Equal emphasis will be put on identifying suitable existing and real world data sets as well as generating new data sets specifically tailored to developing TLP applications.
- Provide open source solutions
- As a technical community, all tools, methods, and recommendations will be made publicly available for review and use.
- Maintain a directory of tools/resources
The Technical Language Processing Community of Interest (TLP COI) is seeking to develop best practices guidelines on how to tailor Natural Language Processing (NLP) tools to technical and engineering text-based data: technical language processing (TLP). Developed guidelines will be technology- and vendor-agnostic and will address the current needs of industry to have independent guidance based on user requirements and measurement science research.
How to Participate in the COI
The TLP COI welcomes members from government, industry, and academia interested in creating better synergy between end users, the research community, and solution providers to reduce complexity, cost, and delay of adoption of TLP solutions. If you are interested in joining the COI, please email tlp-coi [at] nist.gov (tlp-coi[at]nist[dot]gov) and provide your full name, e-mail address, company, and title. Please also provide a short description of "what do you hope to get out of working with this group?"
Communication
The TLP COI uses Slack for asynchronous communication with the group. If you would like to join the Slack workspace, please email tlp-coi [at] nist.gov (tlp-coi[at]nist[dot]gov) to be invited to the workspace.
TLP Resources
The TLP COI has a community-built list of useful TLP resources on GitHub. The community welcomes new submissions to the list, please follow the Contribution Guidelines when submitting. Information on previous events is located on the Events page.
TLP COI GOALS
The TLP COI brings together interested participants to discuss ongoing and future directions for text analysis of technical data. The output from this group will influence guidelines and roadmap documents to improve adoption of TLP solutions.
The TLP COI wants to advance research and development initiatives to advance TLP for smart manufacturing and other industrial applications. The following list defines the scope and focus of the TLP COI:
- Education: highlighting results to the community from research and scientific discoveries of NLP and TLP and their added value to industrial applications;
- Use case management: identifying use cases where NLP can enhance the productivity and reliability of services;
- Validation: developing guidelines and metrics for organizations to evaluate use cases and software solutions;
- Dissemination: developing a public knowledge repository to share results (e.g., source code, tutorial videos, peer-reviewed articles);
- Communication: providing a platform for different stakeholders to find each other, exchange ideas/needs/feedback, ensure goals are met, and foster innovation.
Contacts
-
TLP COI Coordinators
NIST TLP COI Leads
-
(301) 975-2285
-
(301) 975-2450
-
(301) 975-0476