
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
Taking Measure
Just a Standard Blog
Brain-Inspired Computing Can Help Us Create Faster, More Energy-Efficient Devices — If We Win the Race
The human brain is an amazingly energy-efficient device. In computing terms, it can perform the equivalent of an exaflop — a billion-billion (1 followed by 18 zeros) mathematical operations per second — with just 20 watts of power.
In comparison, one of the most powerful supercomputers in the world, the Oak Ridge Frontier, has recently demonstrated exaflop computing. But it needs a million times more power — 20 megawatts — to pull off this feat.
My colleagues and I are looking to the brain as a guide in developing a powerful yet energy-efficient computer circuit design. You see, energy efficiency has emerged as the predominant factor keeping us from creating even more powerful computer chips. While ever-smaller electronic components have exponentially increased the computing power of our devices, those gains are slowing down.
Interestingly, our view of how the brain works has been a source of constant inspiration to the computing world. To understand how we arrived at our approach, we need to take a short tour of computing history.
How a 19th Century Mathematician Launched the Computing Revolution
Mathematician George Boole’s impact on the modern age is incalculable. His 1847 invention, now known as Boolean algebra, assigns 1 and 0 values to logical propositions (true or false, respectively). Boolean algebra describes a way to perform precise mathematical calculations with them.
Boole’s inspiration came from how he understood the brain to work. He imagined the laws of thought as being logical propositions that could take on true (1) or false (0) values. He expressed these laws mathematically, so they could perform arithmetic in a precise, systematic fashion. Many years later, with the research of information scientist Claude Shannon, Boolean algebra was used with electrical switches that we now know as transistors, the building blocks of today’s computers.
Today, tiny, nanometer-sized transistors operating as switches inside microchips are the most manufactured device ever. More than 13 sextillion (one followed by 21 zeros) devices have been fabricated as of 2018. Millions of such transistors are arranged into centralized, flexible architectures for processing data.
These micro-scale processing machines, or microprocessors, are used in nearly anything you use that has a computer — a cellphone, a washing machine, a car or a smartwatch. Their versatility, scalability and robustness have been responsible for their “Swiss Army knife” reputation. They are able to do many things that humans are not well suited to do, such as calculating trajectories of rockets or rapidly crunching numbers in large financial spreadsheets.
In recent years, transistors have gotten a thousand times smaller, a hundred thousand times faster, and able to use a billion times less energy. But these incredible improvements from the early days of computing are not enough anymore. The amount of data that is being produced by human activity has exponentially increased. The centralized Swiss Army-knife approach cannot keep up with the data deluge of the modern age.
On the other hand, our biological evolution over billions of years solved the problem of handling lots of data by using lots of processing elements.
In recent years, transistors have gotten a thousand times smaller, a hundred thousand times faster, and able to use a billion times less energy. But these incredible improvements from the early days of computing are not enough anymore.
While neurons, or nerve cells, were discovered in the late 1800s, their impact on computing would occur only 100 years later. Scientists studying the computational behavior of brains began building decentralized processing models that relied on large amounts of data. This allowed computer engineers to revisit the organization of the brain as a guiding light for rearranging the billions of transistors at their disposal.
The Brain as a Sea of Low-Precision Neurons
The neuron doctrine, as it is known today, envisions the brain as made up of a vast sea of interconnected nerve cells — known as neurons — that communicate with each other through electrical and chemical interactions. They communicate across physical barriers called synapses. This view, popularized by early neuroscientists, is very different from Boole’s more abstract logical view of brain function.
But what are they doing computationally? Enter Walter Pitts and Warren McCulloch.
In 1943, they proposed the first mathematical model of a neuron. Their model showed that nerve cells in the brain have enormous computational power. It described how a nerve cell accumulates electrical activity from its neighboring nerve cells based on their “importance” and outputs electrical activity based on its aggregated input. This electrical activity, in the form of spikes, enables the brain to do everything from transmitting information to storing memory to responding to visual stimuli, such as a family picture or a beautiful sunset. As neurons can have thousands of neighbors, such an approach was well suited to dealing with applications with a lot of input data.
Today, 80 years later, the McCulloch and Pitts model is widely regarded as the parent of modern neural network models and the basis of the recent explosion in artificial intelligence. Especially useful in situations where the precision of data is limited, modern AI and machine learning algorithms have performed miraculous feats in a variety of areas such as search, analytics, forecasting, optimization, gaming and natural language processing. They perform with human-level accuracy on image and speech recognition tasks, predict weather, outclass chess grandmasters, and as shown recently with ChatGPT, parse and respond to natural language.
Historically, the power of our computing systems was rooted in being able to do very precise calculations. Small errors in initial conditions of rocket trajectories can lead to huge errors later in flight. Though many applications still have such requirements, the computational power of modern deep-learning networks arise from their large size and interconnectivity.
A single neuron in a modern network can have up to a couple of thousand other neurons connected to it. Though each neuron may not be as precise, its behavior is determined by the aggregated information of many of its neighbors. When trained on an input dataset, the interconnection strengths between each pair of neurons are adjusted over time, so that overall network makes correct decisions. Essentially, the neurons are all working together as a team. The network as a whole can make up for the reduced precision in each of its atomic elements. Quantity has a quality all its own.
To make such models more practical, the underlying hardware must reflect the network. Running large, low-precision networks on a small number of high-precision computing elements ends up being tremendously inefficient.
Today there is a race to build computing systems that look like regular grids of low-precision processing elements, each filled with neural network functionality. From smartphones to data centers, low-precision AI chips are becoming more and more common.
As the application space for AI and machine learning algorithms continues to grow, this trend is only going to increase. Soon, conventional architectures will be incapable of keeping pace with the demands of future data processing.
Even though modern AI hardware systems can perform tremendous feats of cognitive intelligence, such as beating the best human player of Go, a complex strategy game, such systems take tens of thousands of watts of power to run. On the other hand, the human Go grandmaster’s brain is only consuming 20 watts of power. We must revisit the brain to understand its tremendous energy efficiency and use that understanding to build computing systems inspired by it.
One clue comes from recent neuroscience research where the timing of energy spikes in the brain is found to be important. We are beginning to believe that this timing may be the key to making computers more energy efficient.
The Brain as a Time Computer
In the early 1990s, French neuroscientists performed a series of experiments to test the speed of the human visual system. They were surprised to find that the visual system was much faster than they had previously thought, responding to a visual stimulus in as little as 100 milliseconds. This went against the prevailing notion of how spikes encode information.
The conventional picture suggests that a neuron must receive a long train of spikes from its neighbors, aggregate all of them, and respond. But the time it would take to aggregate a long spike train and respond would be much larger than experimentally discovered. This meant that some neurons were not aggregating long spike trains from neighbors — and conversely, were working with just a couple of spikes from their neighbors when producing an output.
This radically changes that way we think information is encoded. If the brain is using only a few spikes to make decisions, then it must be making decisions based on the timing differences between spikes. A similar process occurs in the auditory systems of humans and other animals. For example, researchers have verified that barn owls use the difference in the arrival times of a sound to each ear to locate their prey.
We must revisit the brain to understand its tremendous energy efficiency and use that understanding to build computing systems inspired by it.
These observations suggest that we might make more efficient computers by mimicking this aspect of the brain and using the timing of signals to represent information.
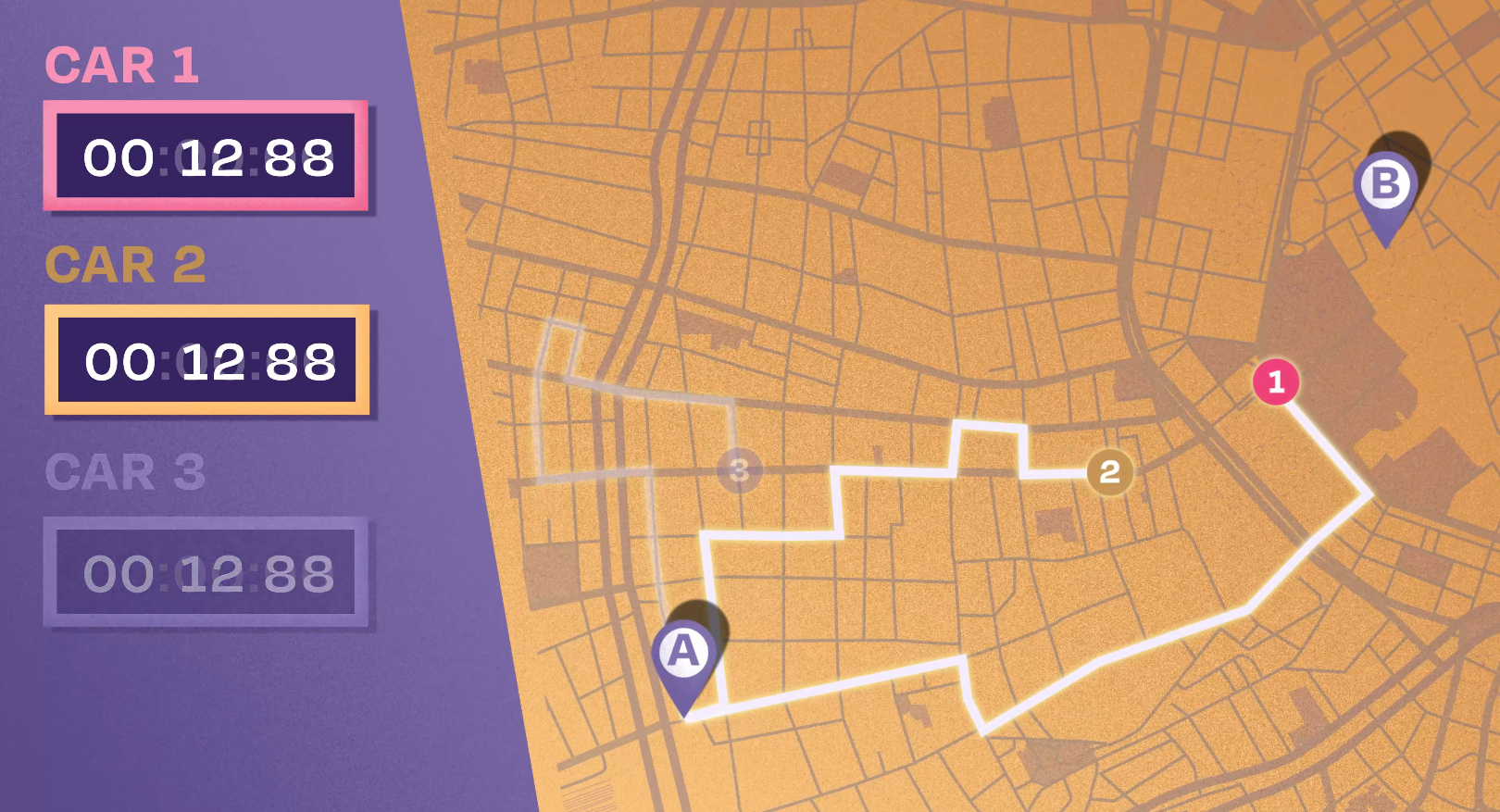
Inspired by this idea, my NIST colleagues and I are aiming to develop a new type of computer circuit that uses something we call “race logic” to solve problems. In race logic, signals race against each other, and the timing between them matters. The winner of the race tells us something about the solution of the problem.
To understand race logic, let’s first go back briefly to conventional computing. Conventional digital computers solve problems by sending Boolean bits of information — 0s and 1s — on wires through a circuit. During circuit operation, bits regularly flip their values, from 0 to 1 and vice versa. Each bit flip consumes energy, and circuits with lots of bit flipping are said to have high activity and consume a lot of energy. Trying to reduce energy consumption suggests reducing activity, hence reducing the number of bit flips to perform a given task.
Race logic reduces activity by encoding information in the timing of those bit flips on a wire. This approach allows a single bit flip on a wire to encode values larger than 0 or 1, making it an efficient encoding.
The circuit could be configured to look like a map between your home and workplace and solve for problems, such as the most efficient route. Electrical signals travel through various pathways in the circuit. The first one to reach the end of the circuit wins the race, revealing the most efficient route in the process. Since only a single bit flip passes through many elements of the circuit, it has low activity and high efficiency.
An additional advantage of race logic is that signals that lose the race by moving through slower routes are stopped, further saving energy. Imagine a marathon where you asked the runners not to run the same route, but for each runner to find the most efficient route to the finish line. Once the winner crosses that finish line, all the other runners stop, saving their own energy. If you apply this to a computer, lots of energy is saved over time.
One important application that race logic is particularly good at solving is the shortest path problem in networks, such as finding the quickest route from one place to another or determining the lowest number of connections required on social media to connect two people. It also forms the basis for complicated network analytics that answer more complex questions, such as highest traffic nodes in networks, path planning for streets in a busy city, the spread of a disease through a population, or the fastest way to route information on the internet.
How did I think to connect brain science to a new type of computer circuit?
The concept of race logic was originally conceived and first practically demonstrated during my Ph.D. thesis work at the University of California, Santa Barbara, guided by the electrical engineering expertise of Professor Dmitri Strukov and the computer science expertise of Professor Tim Sherwood. I am currently working toward exploring mathematical techniques and practical technologies to make this concept even more efficient.
Using Race Logic to Make the Next Generation of Energy-Efficient Computers
Next-generation computers are going to look very different from the computers of yesterday. As the quantity and nature of our data gathering changes, the demands from our computing systems must change as well. Hardware that powers tomorrow’s computing applications must keep energy impacts minimal and be good for the planet.
By being in touch with the latest developments in brain science, next-generation computers can benefit from the recently uncovered secrets of biology and meet the ever-increasing demand for energy-efficient computing hardware.
Our team at NIST is running a race of our own — to help computing power reach its full potential and protect our planet at the same time.
About the author

Related Posts



Comments
Hi, Marshall. Here's a response from the author:
Please refer to appendix A of this document from Oxford on brain emulation. https://www.fhi.ox.ac.uk/brain-emulation-roadmap-report.pdf
This gives a list of what various researchers from different groups think about the computational capabilities of the brain.
Its all in the 10^15 to 10^18 ballpark. Connections, frequencies and bytes per spike can change by an order of magnitude or so.
The brain is an enormously complicated thing, and there are many assumptions that are made when the brain is called a computer.
One group (biologists) are trying to emulate the brain, hence hoping that behaviors can be explained via simulation, while the second group (computer scientists) think that the brain is a computer and anything that the brain does a computer can do. There is a subtle difference between the two. Also, these are deep philosophical questions that I don’t have answers to.
Page 15 of the same document addresses some of these assumptions on the part of the biologists.
Moreover, people don’t know how spikes encode information or if each spike can the thought as a bit, or less, or more. These topics are under active debate since the rate and temporal approaches to spike coding are still being explored.
There are many computational models of the brain and prediction and inferring is one of them. It is also learning while predicting and inferring.
The calculations are back of the envelope and should be taken as an estimate.
Interesting and well-written article! I look forward to more articles.
Fascinating article. Especially in the context of the Nobel prizes for Physics and Chemistry 2024.
I've been shouthing this for long time. I have architected the Drosophila nervous system emulation (127K Neurons) to run on a single laptop. I'm working on a drone (Dronesophila) to prove that the emulation is true. This is a full emulation, not a mathematical simulation. SWaP (Size, Weight and Power) is so important to progress AGI technologies. Why do we want to send humans to Mars? Because we can ask a human to go explore a area and let us know if there is anything interesting. We can't send a fully autonomous robot to Mars with a few semi-trucks of computers or build a nuclear power plant on Mars first and then build huge data centers to get some assemblance of general intelligence and fully autonomous behaviors. Emulations on a small size computing system is key and I am doing my best to prove that out.
In the start, it is said that ",it can perform the equivalent of an Exaflop " What is meant by 'equivalent', and how was this measured?