
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
Cybersecurity Insights
a NIST blog

We are excited to introduce our second guest author in this blog series, Xi He, assistant professor of Computer Science at the University of Waterloo, whose research represents the state of the art in the subject of this blog post: answering queries with joins while preserving differential privacy. - Joseph Near and David Darais
So far in this blog series, we have discussed the challenges of ensuring differential privacy for queries over a single database table. In practice, however, databases are often organized into multiple tables, and queries over the data involve joins between these tables. In this post, we discuss the additional challenges of differential privacy for queries with joins, and describe some of the solutions for this setting.
Queries with Joins
Consider the U.S. Census Bureau, which would like to release employment statistics. An example of a query used to compute these statistics is "how many workers exist with age > 20?" To answer this query, we only need a single database table: the example “Workers” table shown below on the left. What if we need two tables to answer a query though? For example: “how many jobs were filled by employees with age > 20 in 2020?" The “Workers” table only has the demographic information of a worker, and each worker can take multiple jobs (or change jobs). Hence, to answer this query, we need to join the “Workers” table with the “Jobs” table, shown below on the right, matching the P_ID column of the “Workers” table with the P_ID column of the “Jobs” table.
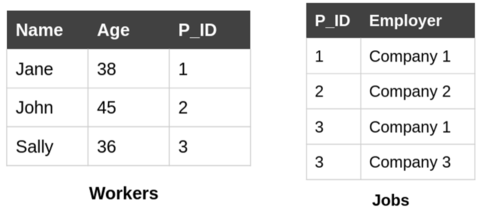
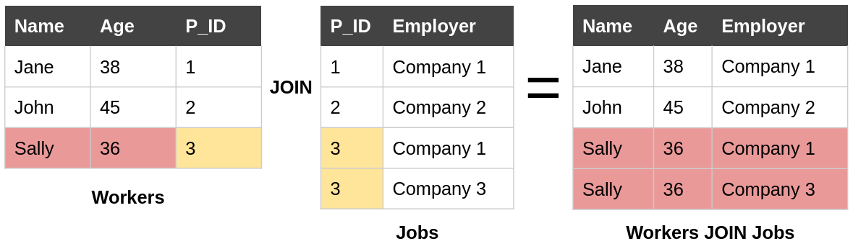
The join of two database tables matches up values in the columns being joined. The output of the join contains one row for each match between the joined tables. In our example, Sally has two jobs - so the P_ID 3 appears twice in the “Jobs” table. This means that Sally’s name and age appears in two rows in the result of the join, shown below.
Challenge for Differential Privacy
For queries of single tables, we can apply the Laplace mechanism introduced in prior posts to perturb the true answer. This query has a sensitivity of one – adding or removing a worker in the “Workers” table affects the count by at most one, and hence adding noise scaled up to this sensitivity will help prevent the adversary from learning the presence or the absence of a worker in this table and offer privacy protection to each worker. However, a counting query over the result of the join has sensitivity that depends on the data. Removing Sally’s record from the “Workers” table would eliminate two rows from the result of the join; if Sally had three jobs, then removing Sally from the workforce would eliminate three rows from the result of the join. The sensitivity of this query is bounded by the maximum number of jobs a worker can take per year - which may be quite large.
Since the sensitivity of queries in this setting depends on the data itself, it can be difficult to bound the sensitivity, and the noise required to ensure differential privacy can be very high, leaving us with useless results. In the rest of this post, we will summarize several solutions that have been proposed to address this challenge, and the software tools which implement them.
Software Tools
Bounding Global Sensitivity via Truncation: Google’s Differential Privacy Library
Conceptually, the simplest solution to ensuring an upper bound on the sensitivity of a query with joins is to limit the number of times a particular value may appear in the columns being joined. In our example above, we might set an upper limit of 5 jobs per person, resulting in a sensitivity of 5 for counting queries over the result of the join. If a person has more than 5 jobs, we keep their 5 randomly selected jobs and discard the rest. This approach is called truncation, because it involves removing rows from the base tables before running the query. Truncation ensures bounded global sensitivity for counting queries on the result of a join.
This approach has been used in a number of research papers, including the PrivateSQL approach detailed later [1]. It has also been implemented in the PostgreSQL module in Google’s open-source differential privacy library. This library allows analysts to write differentially private queries with joins, and truncates base tables to ensure bounded global sensitivity. Google’s open-source differential privacy library is indexed in NIST’s Privacy Engineering Collaboration Space, where you are invited to share feedback or use cases related to these tools.
Bounding Local Sensitivity Using the Data: FLEX
The second approach to ensuring differential privacy in the presence of joins is based on the local sensitivity of the true data. Rather than adding noise scaled to the query’s global sensitivity, this approach adds noise that depends on the true data. The Elastic Sensitivity mechanism [2] is one example for this approach used in a differentially private database system. This approach achieves approximate differential privacy (or (ε,δ)-differential privacy), a relaxed version of differential privacy.
The Elastic Sensitivity approach has been implemented in a mechanism called FLEX [2], that is available as part of the open-source Chorus system. Chorus works with any SQL database, but does not provide plugins for any specific database engine and requires more setup before deployment than Google’s library. Chorus is also indexed in NIST’s Privacy Engineering Collaboration Space, where you are invited to share feedback or use cases related to these tools.
Beyond Row-Level Privacy: PrivateSQL
One issue for privacy with multiple tables is that there are multiple private entities. Besides protecting the privacy of employees, the U.S. Census Bureau also needs to ensure the privacy of the employers. For the query "how many jobs were filled by employees with age > 20 in 2020?”, adding or removing an employer in the “Jobs” table can cause an unbounded change in the number of jobs - even if we make no change to any other tables!
Thus, if we calculate sensitivity based on workers, then we may fail to ensure privacy for employers. If we want to do both, then we need to consider the correlations between private entities and design systems that allow the data curator to flexibly specify entities in the schema that need privacy.
No currently available open-source system provides comprehensive support for the known approaches to ensuring differential privacy for queries with joins. PrivateSQL [1] is one approach that provides fine-grained definitions of privacy relationships in the context of joins, but no open-source implementation is currently available. As differential privacy becomes more broadly deployed, we expect that the available systems for processing queries with joins will become more capable and mature.
Coming up Next
The techniques described so far in this series apply to specific queries over sensitive data - we need to know what queries we want to run in order to apply them. What if we don’t know in advance what queries we will want to run? Our next post will describe techniques for creating differentially private synthetic data - a “privatized” version of a sensitive dataset that approximates the true data while ensuring differential privacy. Once a synthetic dataset has been constructed, it can be analyzed using existing tools and workflows with no additional threat to privacy. Synthetic datasets are particularly useful for analysts who are less familiar with differential privacy, since they can safely be processed without learning new tools or techniques.
This post is part of a series on differential privacy. Learn more and browse all the posts published to date on the differential privacy blog series page in NIST’s Privacy Engineering Collaboration Space.
References
[1] Kotsogiannis, Ios, Yuchao Tao, Xi He, Maryam Fanaeepour, Ashwin Machanavajjhala, Michael Hay, and Gerome Miklau. "PrivateSQL: a differentially private SQL query engine." Proceedings of the VLDB Endowment 12, no. 11 (2019): 1371-1384.
[2] Johnson, Noah, Joseph P. Near, and Dawn Song. "Towards practical differential privacy for SQL queries." Proceedings of the VLDB Endowment 11, no. 5 (2018): 526-539.