
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
Description
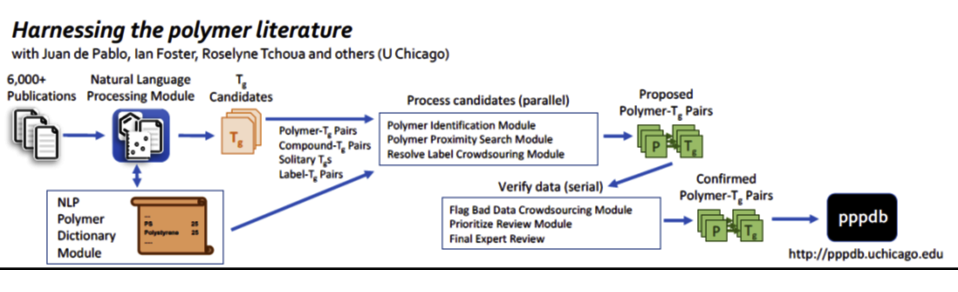
We aim to generate the data necessary for polymer informatics by developing information extraction pipelines to automatically extract polymer properties from the literature. We use natural language processing software (ChemDataExtractor) to extract both names of chemical entities and properties automatically from journal articles.
Efforts are a collaboration between NIST and CHiMaD, specifically computer scientists and polymer physicists at Univ. of Chicago. We are also currently looking at ways of hosting data directly provided by others.
Major Accomplishments
- Database of Flory-Huggins chi parameters and glass transition temperatures available online at http://pppdb.uchicago.edu
- Development of pipelines for extraction of polymer properties from the literature
Additional Technical Details
Ongoing Challenges
- Accurately identifying polymer names from the proposed list of chemical entities
- Extracting necessary contextual information associated with a given property