
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
Cybersecurity Insights
a NIST blog
The UK-US Blog Series on Privacy-Preserving Federated Learning: Introduction
This post is the first in a series on privacy-preserving federated learning.
The series is a collaboration between CDEI and NIST.
Advances in machine learning and AI, fueled by large-scale data availability and high-performance computing, have had a significant impact across the world in the past two decades. Machine learning techniques shape what information we see online, influence critical business decisions, and aid scientific discovery, which is driving advances in healthcare, climate modelling, and more.
Training Models: Conventional vs Federated Learning
The standard way to train machine learning models is to collect the training data centrally, on one server or in one data center, where it can be used to train the model. A model is what we get from the output of training on the data; once trained, a model is then used for predictions or generating new content. For example, a consortium of banks may want to train a model to detect fraudulent transactions; to do so, they’ll need to collect transaction data from many different banks on a central server, as shown in Figure 1(a).
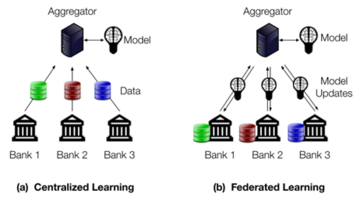
Collecting sensitive financial data raises serious privacy concerns, however. If the central server is compromised or its owner is not trustworthy, then the data may be leaked or used for other purposes. Sharing sensitive information like financial data may not even be possible due to privacy regulations or other legal restrictions. Apart from security and privacy concerns, in some cases the data may raise intellectual property issues.
Because of these challenges, many organizations simply decide to not share data. As a result, useful models—like the fraud detector in our example—are impossible to build.
This blog series focuses on federated learning, an approach that addresses the fundamental privacy challenge of traditional machine learning by avoiding the centralized collection of training data. In federated learning, the central server sends a copy of the partially trained model to each participating organization and collects model updates instead of data, as shown in Figure 1(b). Each organization constructs its model update by training the model locally on its own sensitive data — which never leaves the organization. The resulting model updates can be aggregated and assembled to construct an improved model. This process repeats until the model is trained. Examples of successful use of federated learning include Google’s Gboard, Speech, and Messages, and Apple’s news personalization and speech recognition. However, there are currently limited examples of federated learning being used to enable collaboration between different organizations without direct sharing of data — such a setup has the potential to unlock new use cases that could provide significant societal and economic benefits.
Privacy Challenges in Federated Learning
Even though federated learning helps to address the privacy challenge of centralized data collection, in the past decade, researchers have discovered new kinds of privacy attacks that can recover sensitive training data even when federated learning is used!
- Attacks on model updates: Model updates are determined by the training data. In some cases, it’s possible to recover information about the training data from the model updates used in federated learning.
- Attacks on trained models: The final trained model also reflects the training data. In some cases, it’s possible to infer information about the training data from the trained model, whether or not federated learning was used to train it.
Developing Solutions: The UK-US PETS Prize Challenges
Announced at the inaugural Summit for Democracy in December 2021, the UK-US PETs prize challenges were a collaborative effort between U.K. and U.S. governments to drive innovation in privacy-preserving federated learning (PPFL). Contestants could tackle two high-impact use cases: combating financial crime and responding to public health emergencies. In both cases, contestants were tasked with training a machine learning classifier on a federated dataset, whilst providing end-to-end privacy guarantees.
The winning teams were selected by an independent panel of PETs experts from academia, industry, and the public sector, taking into consideration the quantitative metrics from the evaluation platform, the outcomes from red teaming, and the code and written reports submitted by teams.
The winning solutions were announced at the second Summit for Democracy in March 2023; you can watch the announcement video here, which also provides a really useful animation of the challenge setup. You can learn more about the challenges at the NIST and the UK websites.
Coming up in this blog series
Throughout this series, we plan to present techniques for PPFL alongside lessons learned in the PETs prize challenges. The challenge results demonstrated the increasing practicality of some PPFL techniques — in some cases, these techniques are already being incorporated into commercial products. The results also highlighted areas where existing techniques are not yet practical, and more research is needed.
Over the coming months, we’ll be publishing a number of blogs to provide practical guidance for exploring privacy-preserving federated learning in practice. The series will feature guest authors from organizations involved in the U.K.-U.S. prize challenges, and other leading experts in the field. Topics will include:
- Privacy threat models in federated learning
- Solutions developed during the prize challenges
- Resources for getting started with federated learning
Finally, we want this blog series and our other work in this space to meaningfully contribute to making AI safer and fairer, whilst protecting important shared values such as privacy and autonomy. Through the Atlantic Declaration, the U.S. and U.K. governments have reaffirmed their commitment to developing safe and responsible AI, including further collaboration on privacy enhancing technologies. If you feel you could help us in this ambition, we want to hear from you. Please do get in touch via pets [at] cdei.gov.uk (pets[at]cdei[dot]gov[dot]uk) or PrivacyEng [at] nist.gov (PrivacyEng[at]nist[dot]gov).



