
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
Cybersecurity Insights
a NIST blog

We are excited to introduce our third guest author in this blog series, Dan Kifer, Professor of Computer Science at Penn State. Dr. Kifer’s research spans many topics related to differential privacy and social data, and a selection of his work represents the state of the art in the subject of this blog post: testing methods for detecting differential privacy bugs. - Joseph Near and David Darais
In the last post, we learned that it is fairly easy to introduce bugs in the design and implementation of differentially private algorithms. We also learned that it can be difficult to find them. In fact, in the worst case, it is mathematically impossible to find all privacy bugs. So what’s the point of trying, right?
The good news is that most bugs are fairly easy to detect with a little bit of experimentation. Anyone can do it, by following this three-step process:
- Create a pair of datasets X and Y that differ on one person.
- Identify an outcome to focus on.
- Show this outcome is too frequent or too infrequent when the input is X compared to when it is Y.
Surprisingly, that is all you need to achieve fame and glory. On to the details…
Pairs of Datasets
It is our job to create two datasets X and Y that differ on one person. Is that a lot to ask? Yes, it is. So let’s make them simple -- it turns out that many privacy bugs can be detected with tiny datasets. Let us consider the following application.
We want to privately compute the average age of a group of people. We know the ages are between 0 and 120 (for the lucky ones who celebrate their 121st birthday and beyond, we still record their ages as 120). We know that the average age should therefore be between 0 and 120. This means that we should be able to achieve 𝛆-differential privacy by taking the average age and adding Laplace noise with scale 120/𝛆 (don’t do this in practice, there are much better algorithms out there). Here is some Julia code that does exactly this:
using Distributions
private_avg(ages, epsilon) = sum(ages) / length(ages) + rand(Laplace(0, 200/epsilon))
Two lines of code! Surely there are no bugs here! Let’s test it anyway. What are the simplest datasets X and Y we can create? Well, X can be empty, no people at all. In this case, the ages array will simply be this: []. We can obtain dataset Y by inserting one person, say 120 years old. The corresponding ages array will be [120]. What happens if we call private_avg([120], 0.001)? We could get some strange number like -22928.63670807794 (this is not a bug, it is just very noisy). If we were working with dataset X, we instead would be calling private_avg([], 0.001). What happens here? We would get a long, scary error message because our code divides by 0.
So, this is a bug and is even exploitable. I could use a very small 𝛆 (say 0.0000000001) and ask for: (1) the differentially private average age of all people named Joe Near with birthday 1900/01/01, (2) the differentially private average age of all people named Joe Near with birthday 1900/01/02, etc. (all the way up to 2021/04/31). The only time I wouldn’t get an error is when I am using the correct birthday. Consequently, the software system would think I used a very small expenditure of privacy budget, but in reality, I learn exactly when I need to buy a cake.
To summarize, very simple pairs of datasets X and Y can be used to detect bugs. Look for weird situations: an empty dataset, a dataset with an extreme value, etc. If you let your creativity run wild, you may realize that sometimes you can’t cover all interesting cases with just one pair of datasets. That is ok. You can create multiple pairs of datasets: X1 Y1, X2 Y2, X3 Y3, ... where each X in a pair differs from its corresponding Y by 1 person’s data. We can run a bug finding procedure for each of these pairs of datasets.
Outcomes to Focus on
In the previous example, we focused on a specific outcome, the error message, which always occurred when the input dataset was X and never occurred when the input dataset was Y.
In a more general setting, suppose we are shopping for differentially private mechanisms. Instead of buying a brand-name mechanism, we are tempted by the price of a cheap knock-off. Fortunately, we can try it before we buy it. So, we create a pair of input datasets X, Y that differ on one person’s data. We run the mechanism multiple times with X as the input and count how many times each output has occurred. We then make a pretty plot:
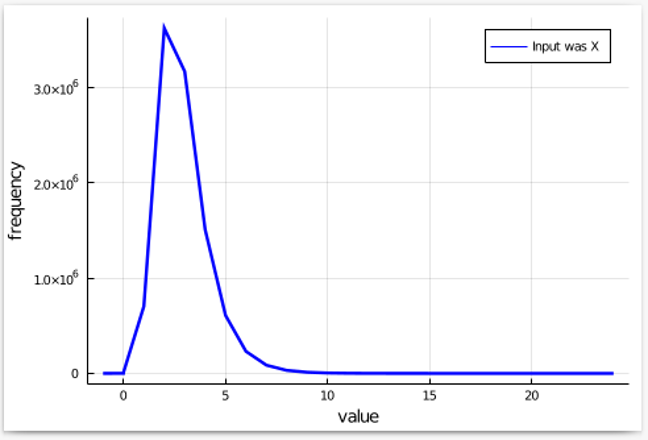
Since we will be doing the same with Y as the input, and then examining the factor by which something becomes more frequent (or less frequent), it is better to view the natural log of the frequencies. This converts multiplication by a factor into addition or subtraction, which is easier on the eyes. Omitting points where the frequency is 0, we get a plot that looks like this:
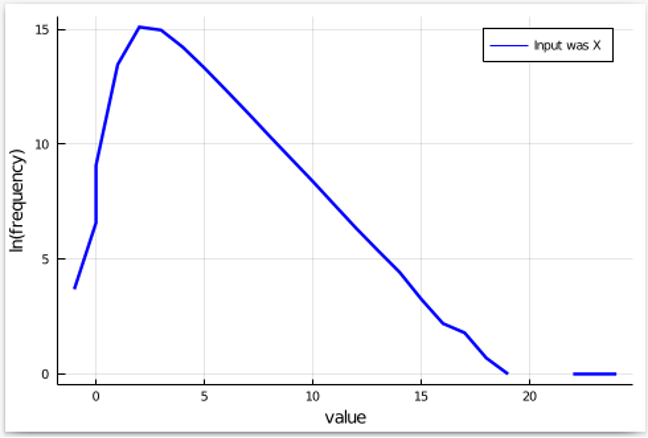
Next, we know that 𝛆-differential privacy allows events to become exp(𝛆) more frequent (or less frequent) as we switch inputs from X to Y. So, let us add these upper and lower bands for our plot:
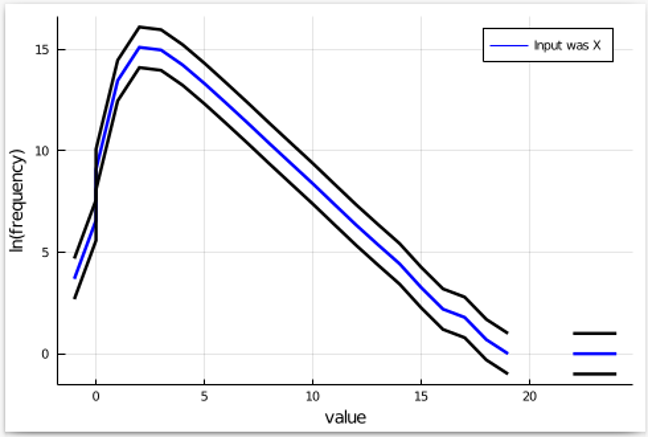
Finally, we run the mechanism multiple times with Y as the input, count the frequency of each output, and add it to this plot. If the mechanism satisfies 𝛆-differential privacy, the plot for Y should be within the black bands. Let’s see what happens:
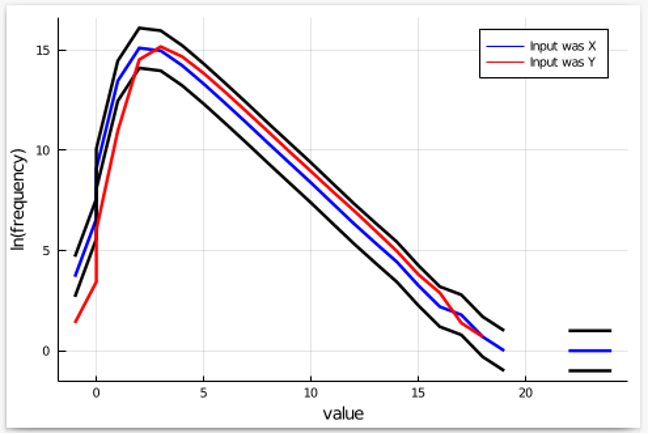
We see that outputs less than 0 appear to be much less frequent than they should be. Hence, the set of outcomes we should be focusing on is the set of outputs that are 0 or less. If we can prove that such outputs are indeed too infrequent when Y is the input, then we prove that our cheap knock-off mechanism does not have the claimed privacy level.
Show the Outcome is Too Frequent or Too Infrequent
Now, it is possible that our observations in the previous figure were entirely due to chance. So, we have two options: either we prove mathematically that outputs less than 0 are much more likely if X is the input compared to Y, or we can run statistical tests that can confirm it. Both approaches are used in existing tools, some of which are described next.
Software Tools
We saw that the general methodology for finding bugs in supposedly differentially private programs consists of identifying good pairs X, Y of input datasets, identifying outcomes to focus on, and then showing that these outcomes are too frequent/infrequent when X is the input instead of Y. All of this can be tedious, time-consuming, and otherwise difficult. Fortunately, there is a long-standing joke that computer scientists are so lazy that they invent software to do their work for them. There are quite a few systems now that can do some of this work. StatDP and DP-Finder were the first to be invented — the discussion in this blog is based on the StatDP methodology. Since then, more powerful systems have been developed: CheckDP, DiPC, and DPCheck — and this list continues to grow.
Coming Up Next
This post focused on advanced testing methods for detecting privacy bugs. One benefit of this approach is that you can establish confidence that privacy is preserved by your program just by observing its input/output behavior over multiple executions. However, as the size of the input or output domain gets large, or the computation becomes expensive to execute, the general approach of testing input/output behavior becomes more difficult to apply. In the next post we’ll discuss another set of techniques for achieving assurance that programs are free of privacy bugs. These approaches utilize program analysis, which examines the program itself — not just input/output behavior — and can give confidence in correct implementation of privacy after just a single execution of the program, or even without running the program at all.
This post is part of a series on differential privacy. Learn more and browse all the posts published to date on the differential privacy blog series page in NIST’s Privacy Engineering Collaboration Space.