
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
SRE12 Results
Disclaimer
These results are not to be construed, or represented as endorsements of any participant's system or commercial product, or as official findings on the part of NIST or the U.S. Government. Note that the results submitted by developers of commercial SR products were generally from research systems, not commercially available products. Since SRE12 was an evaluation of research algorithms, the SRE12 test design required local implementation by each participant. As such, participants were only required to submit their system output to NIST for uniform scoring and analysis. The systems themselves were not independently evaluated by NIST.
The data, protocols, and metrics employed in this evaluation were chosen to support SR research and should not be construed as indicating how well these systems would perform in applications. While changes in the data domain, or changes in the amount of data used to build a system, can greatly influence system performance, changing the task protocols could indicate different performance strengths and weaknesses for these same systems.
Because of the above reasons, this should not be interpreted as a product testing exercise and the results should not be used to make conclusions regarding which commercial products are best for a particular application.
The goal of the NIST Speaker Recognition Evaluation (SRE) series is to contribute to the direction of research efforts and the calibration of technical capabilities of text independent speaker recognition. The overarching objective of the evaluations has always been to drive the technology forward, to measure the state-of-the-art, and to find the most promising algorithmic approaches.
NIST has been coordinating Speaker Recognition Evaluations since 1996. Since then over 75 research sites have participated in our evaluations. Each year new researchers in industry and universities are encouraged to participate. Collaboration between universities and industries is also welcomed.
NIST maintains a general mailing list for the Speaker Recognition Evaluation. Relevant evaluation information is posted to the list. If you would like to join the list or have any question for NIST related to our speaker recognition evaluation, please e-mail us at speaker_poc [at] nist.gov (speaker_poc[at]nist[dot]gov).
The 2012 evaluation was administered as outlined in the official SRE12 evaluation plan. The sections below are taken from the evaluation plan, please see it for more detail. We also have made available a brief presentation.
Evaluation Task
The year 2012 speaker recognition task was speaker detection, as described briefly in the evaluation plan. This has been NIST's speaker recognition task over the past sixteen years. The task was to determine whether a specified target speaker is speaking during a given segment of speech. More explicitly, one or more samples of speech data from a speaker (referred to as the "target" speaker) were provided to the speaker recognition system. These samples were the "training" data. The system used these data to create a "model" of the target speaker's speech. Then a sample of speech data was provided to the speaker recognition system. This sample was referred to as the "test" segment. Performance was judged according to how accurately the test segment is classified as containing (or not containing) speech from the target speaker.
In previous NIST evaluations the system output consisted of a detection decision and a score representing the system's confidence that the target speaker is speaking in the test segment. NIST has recently encouraged expressing the system output score as the natural logarithm of the estimated likelihood ratio, defined as:
LLR = log (pdf (data | target hyp.) / pdf (data | non-target hyp.))
Because of the general community acceptance of using the log likelihood ratio as a score, in SRE12 NIST required that the system output score for each trial be the natural logarithm of the likelihood ratio. Further, since the detection threshold could be determined from the likelihood ratio, system output in SRE12 did not include a detection decision.
Evaluation Tests
The speaker detection task for 2012 was divided into nine distinct and separate tests. Each of these tests involved one of three training conditions and one of five test conditions. One of these tests was designated as the core test.
Evaluation Conditions
Training Conditions
Target speaker training data in SRE12 comprised of all of the speech data associated with the target speakers chosen from the LDC speaker recognition speech corpora used in previous SRE's. There were 1918 target speakers. A list of target speakers was supplied, along with the relevant LDC speech corpora, when participants registered to participate in the SRE12 evaluation. In addition, some previously unexposed target speakers, along with their relevant speech training data, were also supplied at evaluation time. These additional speakers had only one training segment. It should be noted that no additional restrictions were placed upon the use of these previously unexposed target speakers; in particular, knowledge of these targets was allowed in computing each trial's detection score.
The three training conditions that were included involved target speakers defined by the following data:
- core: All speech data, including microphone and telephone channel recordings, available for each target speaker.
- telephone: All telephone channel speech data available for each target speaker. This condition prohibited the use in any way of the microphone data from any of the designated target speakers. Microphone data from speakers other than those specified as target speakers could be used, for example, for background models, speech activity detection models, etc.
- microphone: All microphone channel speech data available for each target speaker. This condition prohibited the use in any way of the telephone data from any of the designated target speakers. Telephone data from speakers other than those specified as target speakers could be used, for example, for background models, speech activity detection models, etc.
Test Conditions
The test segments in the 2012 evaluation were mostly excerpts of conversational telephone speech but also contained interviews. There will be one required and four optional test segment conditions:
- core: One two-channel excerpt from a telephone conversation or interview, contained nominally between 20 and 160 seconds of target speaker speech. Some of these test segments had additive noise imposed.
- extended: The test segments will be the same as those used in Core. The number of trials in Extended tests exceeded the number of trials in Core tests.
- summed: A summed-channel excerpt from a telephone conversation or interview, contained nominally between 20 and 160 seconds of target speaker speech formed by sample-by-sample summing of its two sides.
- known: The trial list for the known test segment condition was the same as in Extended. The system presumed that all of the non-target trials are by known speakers.
- unknown: The trial list for the unknown test segment condition was the same as in Extended. The system presumed that all of the non-target trials are by unknown speakers.
The matrix of training and test segment condition combinations is shown below. Note that only 9 (out of 15) condition combinations were included in the 2012 evaluation. Each test consisted of a sequence of trials, where each trial consisted of a target speaker, defined by the training data provided, and a test segment. The highlighted text labeled "required" was the core test for the 2012 evaluation. All participants submitted results for this test.
| Training Condition | ||||
|---|---|---|---|---|
| Core | Microphone | Telephone | ||
| Test Segment Condition | Core | required (Core test) | optional | optional |
| Extended | optional | optional | optional | |
| Summed | optional | |||
| Known | optional | |||
| Unknown | optional | |||
Common Evaluation Conditions
In each evaluation NIST has specified one or more common evaluation conditions, subsets of trials in the core test that satisfy additional constraints, in order to better foster technical interactions and technology comparisons among sites. The performance results on these trial subsets were treated as the basic official evaluation outcomes.
Because of the multiple types of test conditions in the 2012 core test, and the disparity in the numbers of trials of different types, it was not appropriate to simply pool all trials as a primary indicator of overall performance. Rather, the common conditions to be considered in 2012 as primary performance indicators included the following subsets of all of the core test trials:
- All trials involving multiple segment training and interview speech in test without added noise in test.
- All trials involving multiple segment training and phone call speech in test without added noise in test.
- All trials involving multiple segment training and interview speech with added noise in test.
- All trials involving multiple segment training and phone call speech with added noise in test.
- All trials involving multiple segment training and phone call speech intentionally collected in a noisy environment in test.
Evaluation Rules
Participants were given a set of rules to follow during the evaluation. The rules were created to ensure the quality of the evaluation and can be found in the evaluation plan.
Performance Measure
The primary performance measure for SRE12 was a detection cost, defined as a weighted sum of miss and false alarm error probabilities. There were two significant changes from past practice regarding how this primary cost measure was computed in SRE12:
First, no detection decision output was needed because trial scores were required to be log likelihood ratios. Thus the detection threshold was a known function of the cost parameters, and so the trial detection decisions were determined simply by applying this threshold to the trial's log likelihood scores.
Second, the primary cost measure in SRE12 was a combination of two costs, one using the cost parameters from SRE10 and one using a greater target prior. This was intended to add to the stability of the cost measure and to increase the importance of good score calibration over a wider range of log likelihoods.
CDet = CMiss × PTarget × PMiss|Target + CFalseAlarm × (1-PTarget) x (PFalseAlarm|KnownNonTarget × PKnown + PFalseAlarm|UnknownNonTarget x (1-PKnown))
Speaker Detection Cost Model Parameters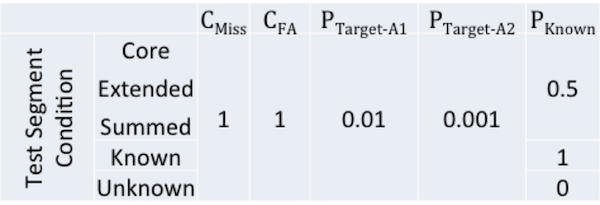
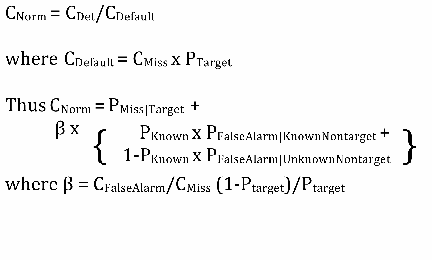
More information on the performance measurement can be found in the evaluation plan.
Results Representation
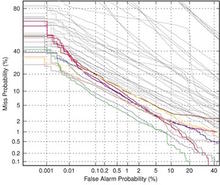
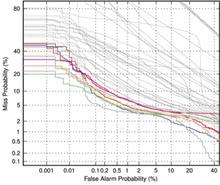
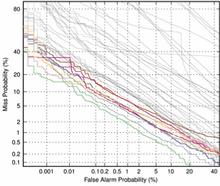
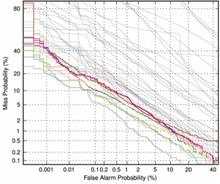
Detection Error Tradeoff (DET) curves, a linearized version of ROC curves, were used to show all operating points as the likelihood threshold is varied. Two special operating points — (a) the system decision point and (b) the optimal decision point — are plotted on the curve. More information on the DET curve can be found in a paper by Martin, A. F. et al., "The DET Curve in Assessment of Detection Task Performance", Proc. Eurospeech '97, Rhodes, Greece, September 1997, Vol.4, pp. 1899-1903.
Evaluation Results
The graphs below show the results for all sites' primary systems for core test and each of the common conditions. The common conditions reference the conditions found in the Common Evaluation Condition section.
| Tests | Conditions | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Common Condition 1 | Common Condition 2 | Common Condition 3 | Common Condition 4 | Common Condition 5 | |||||
| core |
|
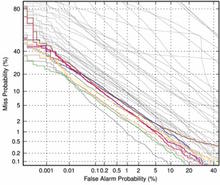
|
|
|
| ||||