
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
Summary
We are witnessing the emergence of a web based "data rich" era on chemical and biological compounds. In order to make significant advances in this "data rich" era, it is essential that there be techniques that allow interoperable annotation, query, and analysis across diverse data; a plug-and-play scalable annotation and adoptive query tool environments that facilitates seamless interplay of tools and data; and versatile user interfaces that allows researchers to annotate, visualize and present the results of analysis in the most intuitive and user-friendly manner.
The principal difficulty in searching data on compounds is that structural features of interest to a user often cannot be defined (and indexed) in advance due to the natural complexity of structure/property relations, which can depend on discipline, task and user. The goal is to develop adaptive, automated method of processing and presenting Biological and Chemical data using connection tables that are sufficiently flexible and easy-to-use and allow users to find, with confidence, information for the most structurally-relevant data used in structure-based drug design.
Description
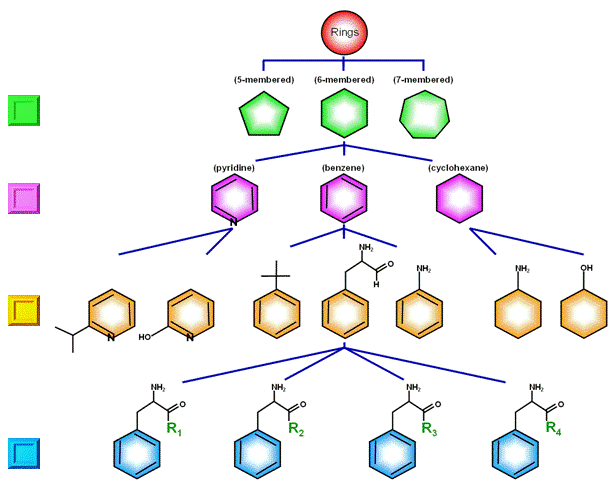
Hierarchy through which individual chemical compounds can be structurally related to a chemically similar compounds, moieties and concepts.
Some of the current projects are
a) http://xpdb.nist.gov/hivsdb/hivsdb.html HIVSDB
b) http://bioinfo.nist.gov/SemanticWeb_pr2d/chemblast.do HIVSDB Chem-BLAST
c) http://bioinfo.nist.gov/biofuels/ A resource for Biofuels
d) http://xpdb.nist.gov/pdb/chemblast.html A ligand gateway for the Protein Data Bank (http://www.rcsb.org/pdb/home/home.do)
e) http://xpdb.nist.gov/image/cell_image.html A reference database for cell images
f) http://xpdb.nist.gov/enzyme_thermodynamics/enzyme_thermodynamics_data.h… Enzyme thermodynamics database
HIVSDB (a) – (b) is the only 3-D structural database dedicated to AIDS research around the world and its aim is to help to elucidate enzyme/drug interaction for the purpose of drug design and development. Biofuels database (c) is a structural resource for biofuels research. PDB ligand gateway (d) is the largest collection of 3-D structures of ligands of interest to technological development and this database serves as ligand gateway for the Protein Data Bank. (e) This is a new effort aimed at developing Semantic Web technology and reference data for cell images with particular emphasis to ontology to foster on-line analysis of the data. The Enzyme thermodynamics database (http://xpdb.nist.gov/enzyme_thermodynamics) provides a compilation of data on the thermodynamics of enzyme-catalyzed reactions and these data play an important role in the prediction of the extent of reaction and the position of equilibrium for any process in which these reactions occur. Student will have opportunity to learn many aspect of state of the art Bioinformatics efforts with specific emphasis to hot topics such as AIDS and Industrial Biotechnology
A considerable part of all the above bioinformatics efforts is on new tools and technology development with particular emphasis to Semantic web technology (http://esw.w3.org/topic/HCLS/ChemicalTaxonomiesUseCase), data interoperability and data standards across multiple Web pages. A new method called Chem-BLAST (Chemical Block Layered Alignment of Sub-structure Technique, recent publications are at (http://xpdb.nist.gov/hiv2_d/download.html) has been developed and implemented in many of the structural databases mentioned above. This method presents the structures held in the database as visual images using 'use case' based ontological tree of its substructures (http://bioinfo.nist.gov/SemanticWeb_pr2d/chemblast.do). These ontological trees facilitate seamless integration, annotation and linking of structural data across the Web. Using this method contents (including all the structures) can be examined and queried using hyper-links on their images ('a picture is worth thousand words') (http://xpdb.nist.gov/pdb/chemblast.html) and it thus circumvents the use of confusing and non-uniform names of the chemical compound to query a compound.